Pocster
-
Posts
14367 -
Joined
-
Last visited
-
Days Won
29
Everything posted by Pocster
-
Precisely ! Not coding , not design - prompt writing ! Even that as you say can written by a more capable llm . Limitation is now human imagination!!!!
-
Oh absolutely! Remember “ i’m free “ not in an are you being served way ! 😂 . No budget limit ( well maybe a bit ) , no time constraint , no boss ( like my build ) so able to explore and experiment! . Create what I want . Equally my house is the sandbox and I’m the guinea pig ! . Perfect setup for the experiment!!
-
😊👍
-
I think there’s confusion here 😊 I want local - even ( obviously that a cloud based version ) is best . i use ChatGPT as my cloud based reasoner and sometimes coder for unlimited tokens ( effectively ) for £20 a month . It’s also my ‘chat’ for architecture / design / free balling ideas . That coupled with local Deepseek / qwen ( when needed ) is working fine . Home assistant can do some of this yes ; Alexa can do some of what I want . But I want to go beyond that … as examples ” it’s hot in here isn’t it Avalon ? “ ” how often was the gate opened last Tuesday Avalon ? “ ” Avalon , play that album by Coldplay I played yesterday “ then …. we get reasoning and memory for example on when to put the radio on . I.e a weighted graph ( doesn’t require an llm admittedly) based on occupancy, time of day , whom is in the room etc Ilm linked to camera above kitchen worktop to see the ingredients and suggest / recognise the meal . leading to stt permanently. SWMBO mentions “ bathroom light didn’t come on again “ this is stored and can referenced later . “ I need to order a usb cable “ . Again stored / referenced . My email checked for the Amazon order etc local llm , home assistant , ip camera , voice/speech recognition all part of the bigger picture . My “ to do “ list is long . Then we move into a humanoid robot to physically do tasks . You guys are focusing on “coding “ that bits solved . I never need to code again . So any method that’s cheap and/or local is perfect . The big picture is much much bigger !! < evil laugh > 😆
-
As an aside a few months ago whilst testing models with chat we defined some test spec and did a prompt for it . The coder produced ok code but a bit amateurish. Chat then re did the prompt . The coder model code was much more robust and professional- on my level ! . Went back to chat and did a full deep prompt . The coder then produced top grade software engineering code . I could do that , but it would take weeks . Chat was demonstrating a poor prompt is more problematic than a poor coding model . So I make sure prompts are solid !
-
My issue was cost per month for number of tokens I use . Also I need llm local to do stt realtime . I’m not suggesting local models match frontier yet ( if ever ! ) but with a bit of workflow adjustment you can get pretty far . ChatGPT plus blows my mind for £20 a month . This I use as my co boss to check everything . I think the media gets obsessed with “ the best “ - but you get to a point where it’s clearly good enough for your needs . I’ve done advanced physics / rendering / maths solely with ChatGPT and it was fantastic . Required work to get it to do it correctly and not (expletive deleted) up . So I’ve changed my workflow ; it’s now better and more efficient. Ultimately I’ll ditch ChatGPT when my local reasoner is good enough . Like all cloud based stuff , line drops , timeouts , stalls , delays I.e workflow rather than model issues wasted more time than a slow model !
-
Honestly! As an ex software engineer I’m stunned ! We binned qwen coder . Too many silly errors . Uma8 microphone array up and recognises “ hey jeaves “ - tomorrow custom wake word . Seems stable as is but will leave running overnight. Have a fully fledge subscription protocol running so any new features easy to add and unlikely to bust anything else . So the Skeleton seems good ! stt should be easy . Was going porcupine route but it’s subscription so went openwake and whisper . My rules is no cost and no cloud - (expletive deleted) that ! To build an entire system with me manually doing zero coding is still insane 🤯
-
I messaged him direct said he’d do it for 27k outside ebay 😂😂😂😂
-
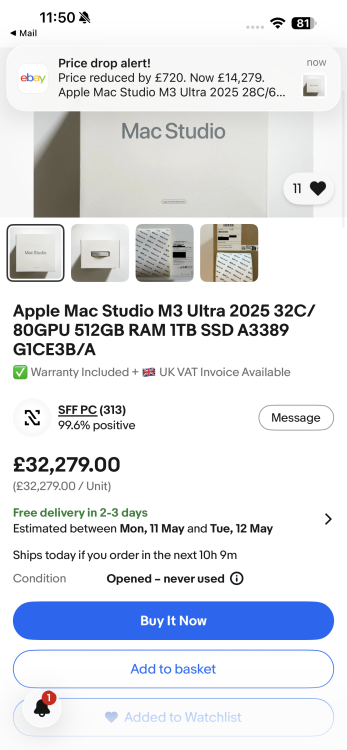
I emailed him . Seeing if there was some wriggle room on the price ( just for fun ) . It’s a bit cheaper now ! 🤣
-
He has a 256gb version which is only £15k . £20k premium for 256gb extra ….
-
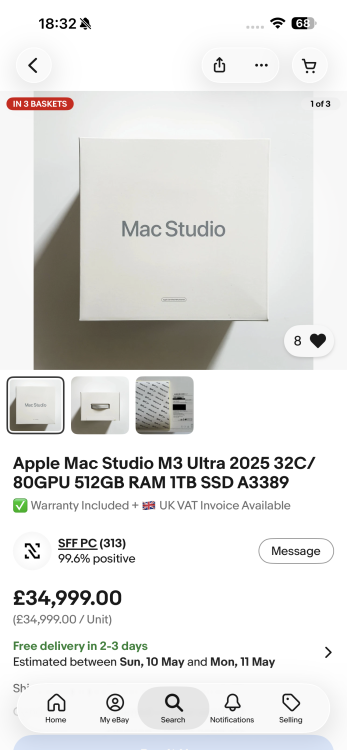
Bet @Nickfromwales bought it !
-
I like a flip , but …. Piss take !
-
Progress has been interesting . qwen coder is a bit spazzy at writing code from prompts - too many errors . We have a pipeline where automatically the error goes to derpseek that rewrites the prompt for coder again ! But at this stage ChatGPT reins king ; it defines and (expletive deleted) me ! Makes me test every single step . It does the code as it’s small snippets and documents them a bit too much ! But it’s a rock solid implementation. Proper SE stuff ! . So structure / framework at this stage is complete . Added the uma8 multi microphone array . All good . In the next few days expect the engineer dashboard to show wake word recognised , stt . At that point things get interesting . It’s going to be a massive project in complexity and I’m in awe what one person can achieve with llm . Will swap back to deep seek and a better coder model when I get something with more ram - which could be some wait ; though I do smell an m5 ultra flip opportunity…. 😊
-
Coder who uses llm absolutely! . It’s not about writing code anymore - as I said it’s orchestration of the llm ! ( using the tool ) The issue I see is less juniors / graduates and when ‘ seasoned ‘ programmer / se retire who carries the knowledge/ understanding forward ?
-
Yes, and China has already started grappling with this. Chinese courts have reportedly ruled that companies cannot simply fire someone purely because AI can do the job cheaper. That proves this is not just imaginary pessimism — governments and courts are already seeing AI replacement as a labour-market issue. And that is exactly my point. If AI were merely “another productivity tool”, why would courts need to decide whether workers can be dismissed because an AI system now performs the role? The fact they are having to rule on it shows the disruption is real. It may make the cake bigger overall, but it can still destroy specific jobs, squeeze wages, and collapse small teams into one person plus AI. That is a major structural change, not just canals becoming railways.
-
Another point is the speed of improvement. I accept local LLMs are not frontier models. They are behind the best cloud systems. But the pace is ridiculous. Every few weeks there seems to be a better open/local model, better quantisation, better tooling, better context handling, better coding ability, or better inference speed. That matters because the argument is not “can today’s model replace everyone?” The argument is “where is this going over the next 3, 5, or 10 years?” I’ve never personally seen a technology move this fast. With most technologies you get gradual product cycles. With LLMs, the capability jump over months is noticeable. A model that felt barely useful a year or two ago can now write, debug, explain, summarise, plan and generate code well enough to materially change how one person works. So yes, today’s local models are not AGI and not frontier. But the gap is closing fast enough that dismissing this as just another normal productivity tool feels complacent.
-
I agree it can make the cake bigger. I’m not saying AI is only bad or that we should ignore it. But “the cake gets bigger” doesn’t mean the slices are evenly distributed. Yes, canals to railways to roads changed employment. But those transitions still destroyed some jobs, shifted power, and forced people to retrain. The fact society eventually adapted doesn’t mean the disruption wasn’t real for the people caught in it. The difference here is speed and breadth. LLMs are not replacing one transport system with another. They touch almost every desk-based industry at once: coding, admin, sales, marketing, support, accounts, legal prep, design, analysis, documentation. My own project is a good example. What would once have needed a small team is now potentially one person directing an LLM, with the AI doing much of the manual coding and iteration. That is brilliant for me as the person using it, but it also means fewer people are needed to produce the same output. So yes, learn to use it. I completely agree. But that doesn’t remove the labour-market issue. In fact it proves it: those who use it well become far more productive, and those who don’t are under pressure. That is not just “another technology” in a mild sense. That changes the structure of work.
-
My project would be a small team . Now it’s 1 person who doesn’t need to manually code . Just this in its own changes everything
-
Quite possibly . You also have to take into account your context window ( chat bot window ) so it depends exactly on what your use is for llm . You can go really small I.e low ram footprint but you are comprising reasoning and accuracy . So it really does depend on intended use . Run in 8gb , yes , useful ? Depends on use .
-
Maybe — but I think that understates what’s different this time. Most past technologies made human labour more productive. LLMs do that too, but they also start to substitute for parts of knowledge work: drafting, coding, support, admin, research, analysis, design, marketing, legal prep, teaching material, etc. That doesn’t require full AGI. You don’t need a conscious machine to reduce headcount; you only need a tool that lets one person do the work that previously needed three, or lets a cheaper worker do work that previously needed a specialist. So even if LLMs are “only” productivity tools, the labour-market effect can still be huge. The Industrial Revolution didn’t replace every worker overnight either — it reorganised whole industries, compressed wages in some areas, created new winners, and made old skills less valuable. My concern isn’t that every job vanishes tomorrow. It’s that large areas of white-collar work become more automated, more competitive, and need fewer entry-level people. That alone is enough to be disruptive without invoking AGI. My project would be a small team . Now it’s 1 person who doesn’t need to manually code . Just this on its own changes everything - a hobby project that proves the workflow …
-
Tricky on Mac and windows . You have to remember Mac is more lean than windows . Linux leaner - but more work . I wouldn’t fight this aspect tbh
-
Good ! This thread is about llm’s - they require Ram thanks though @JohnMo fo
-
For a programmer / SE certainly junior roles have been reduced significantly. Why employ someone when a llm can do it ? . There’s virtually no need to write code anymore 🤯. No need to learn all the libraries . Now it is orchestration for the human . I discussed this with ChatGPT . It worded it as coding is now cheap and virtually no labour required ! I’m in a fortunate position as I can experiment, spend money , no boss , endless end goal , no risk . Chat agrees that my full project would require pre llm a small team of programmers and would take years to develop . Now there’s one , me , zero code to do . 🤯🤯🤯. For reference as I have only 96gb I have the smallest possible context windows. This apart from reducing ram requirements also avoid hallucinations. Deepseek and qwen are fed fresh prompt each time not historical reference required . ChatGPT of course needs the history / context - but produces no code . I’ll say it again , it’s insane !
-
Right , now, let’s do this slowly I didn’t check every website on Earth . You need enough ram to be useful . 24gb once booted won’t leave a lot for a useful llm . local llm can even be installed on a pi for example . The keyword is useful - in essence you’d want 64gb min on a Mac as it uses unified ram . People run these things on much less . These units and above have all but disappeared. Ultra m3 ( go check ) on eBay ( assuming they have real stock ) are on for 5k base model prices . So that’s 1k more than Apple retail them for . Openclaw etc has made a lot of people punt on a relatively cheap Mac mini to experiment with .
-
I’ll give you a 69