Pocster
-
Posts
14385 -
Joined
-
Last visited
-
Days Won
29
Everything posted by Pocster
-
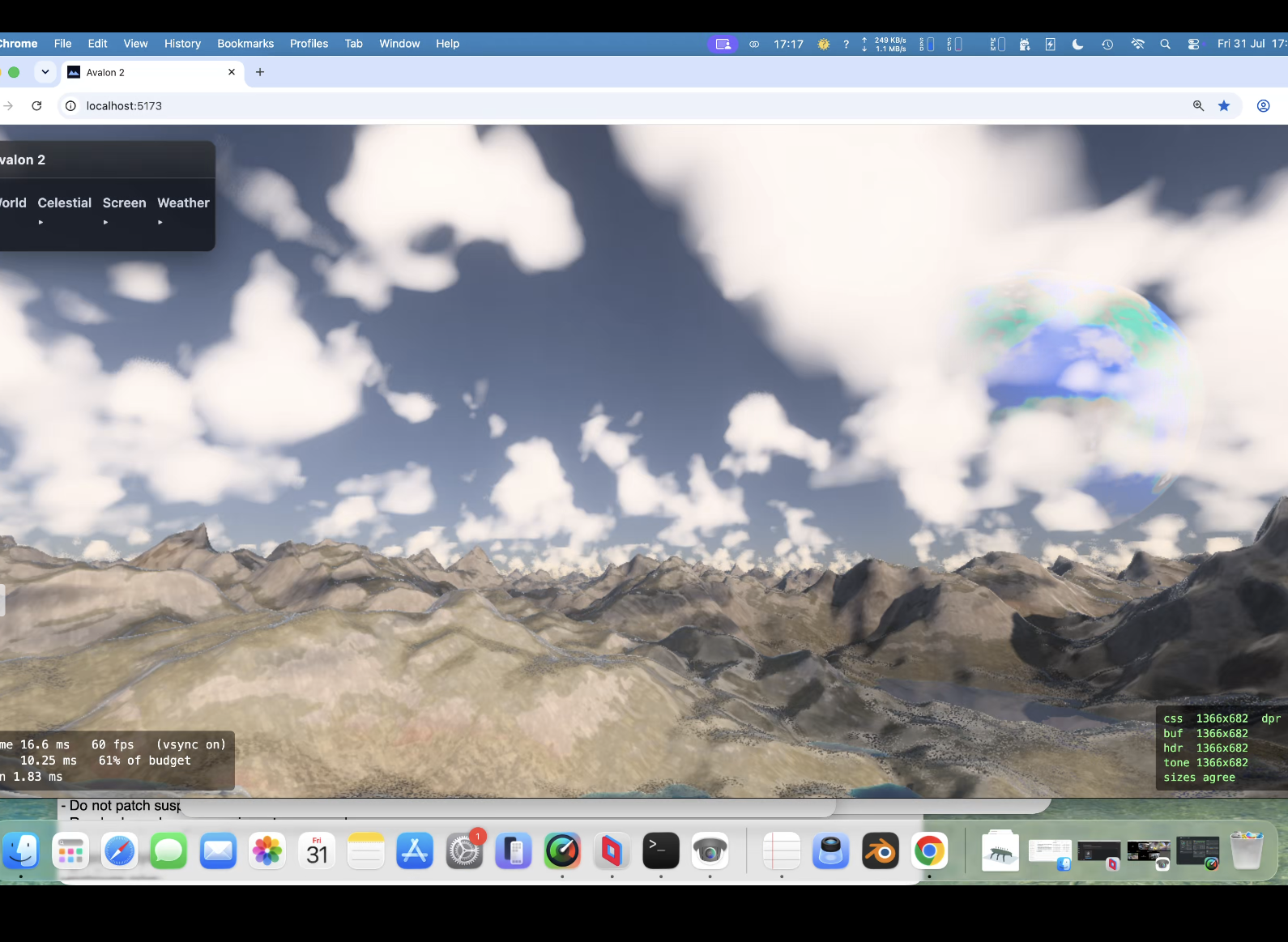
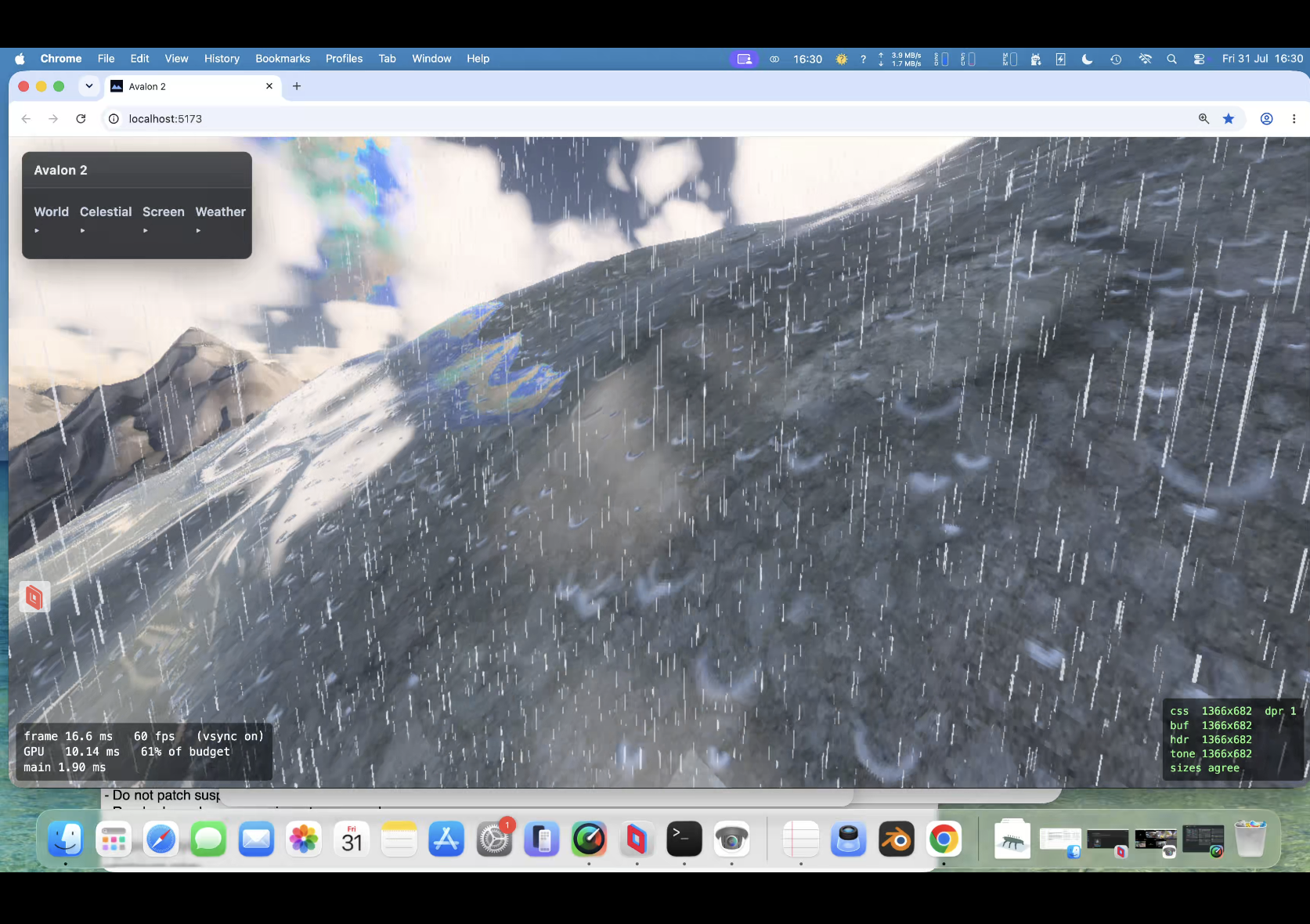
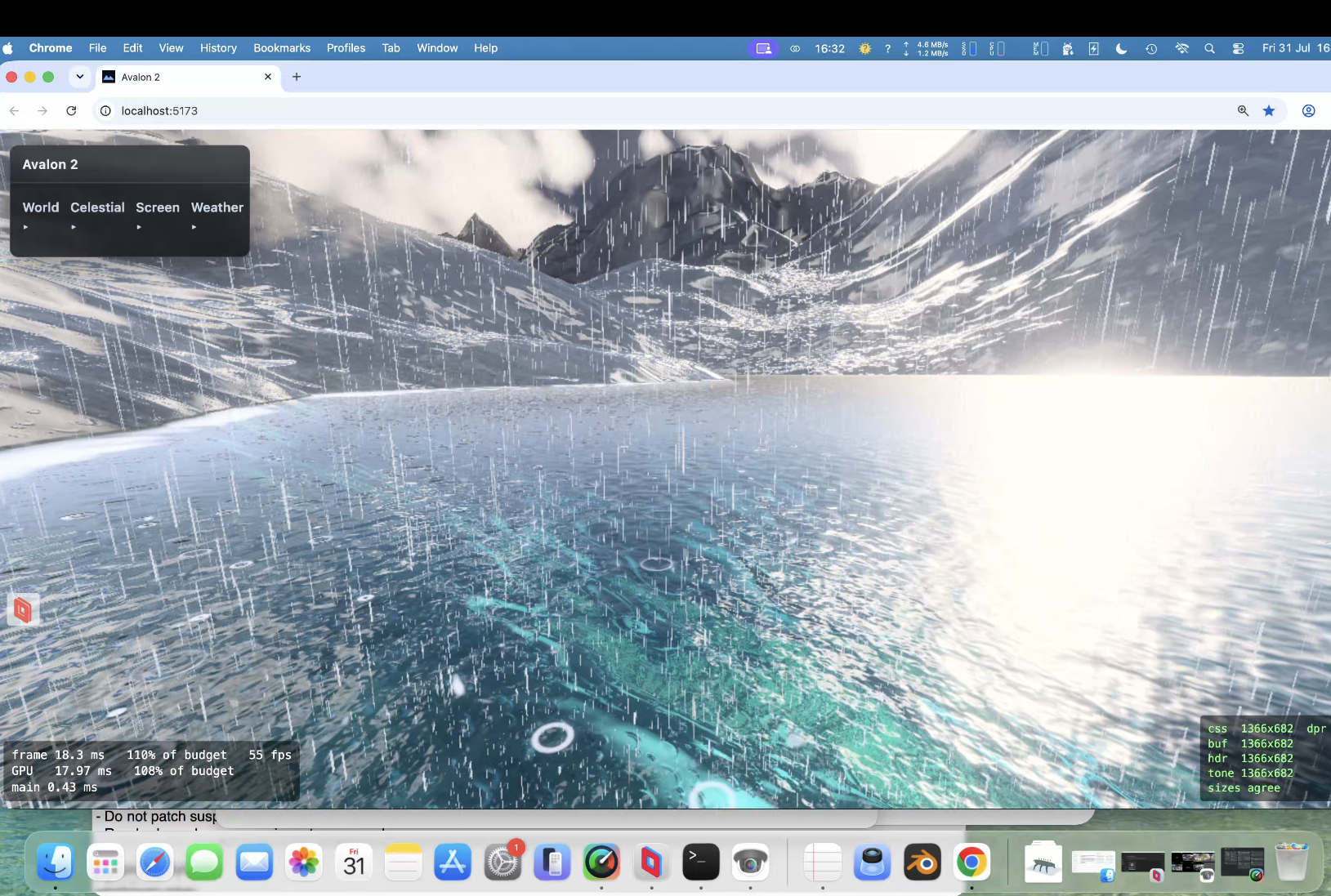
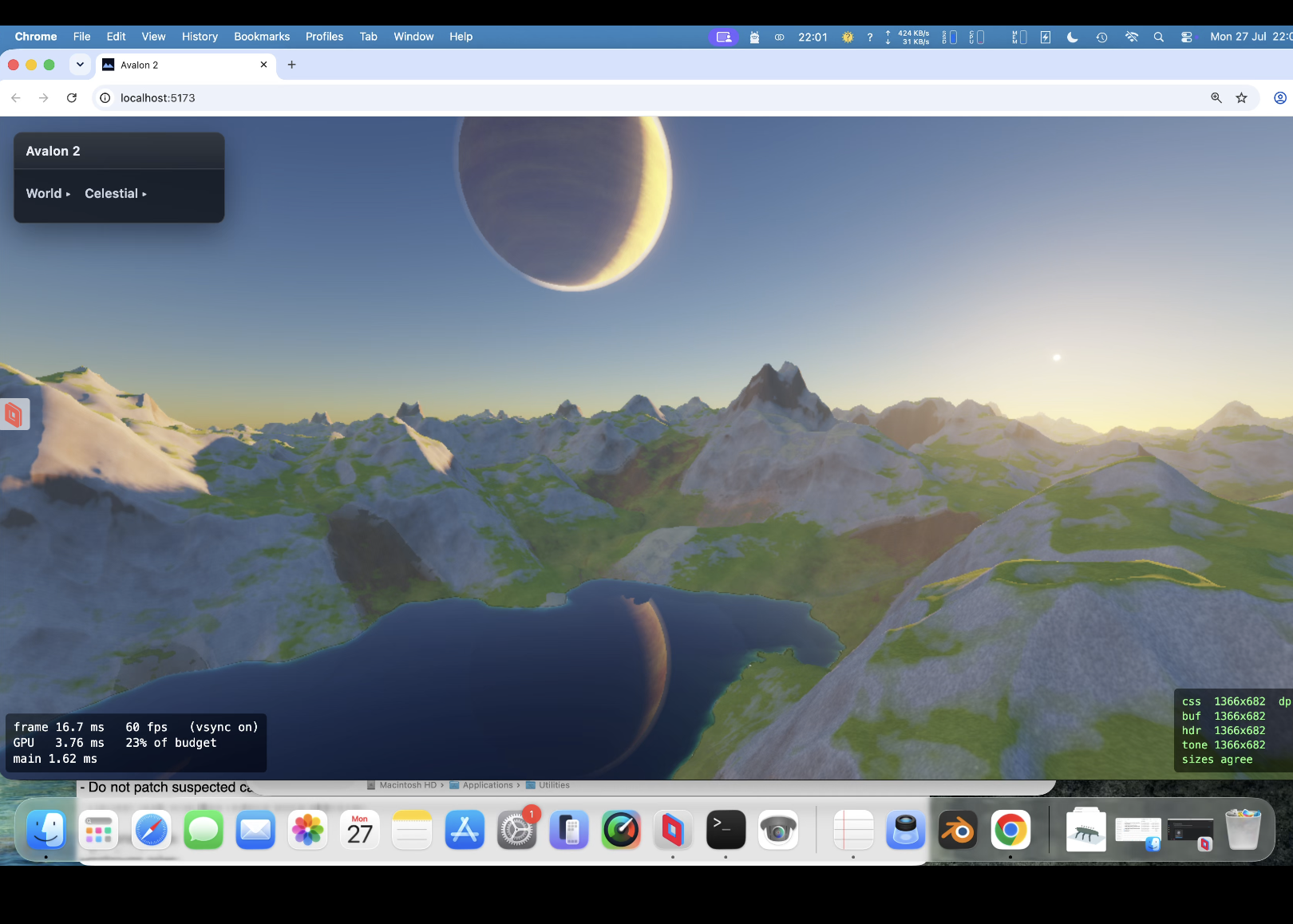
Oh yes and the amazing cube marched clouds. VERY expensive! need to optimise again soon !. Lit!, can have a nice storm with them! Which means a detour (as usual) to .... lightening!!!
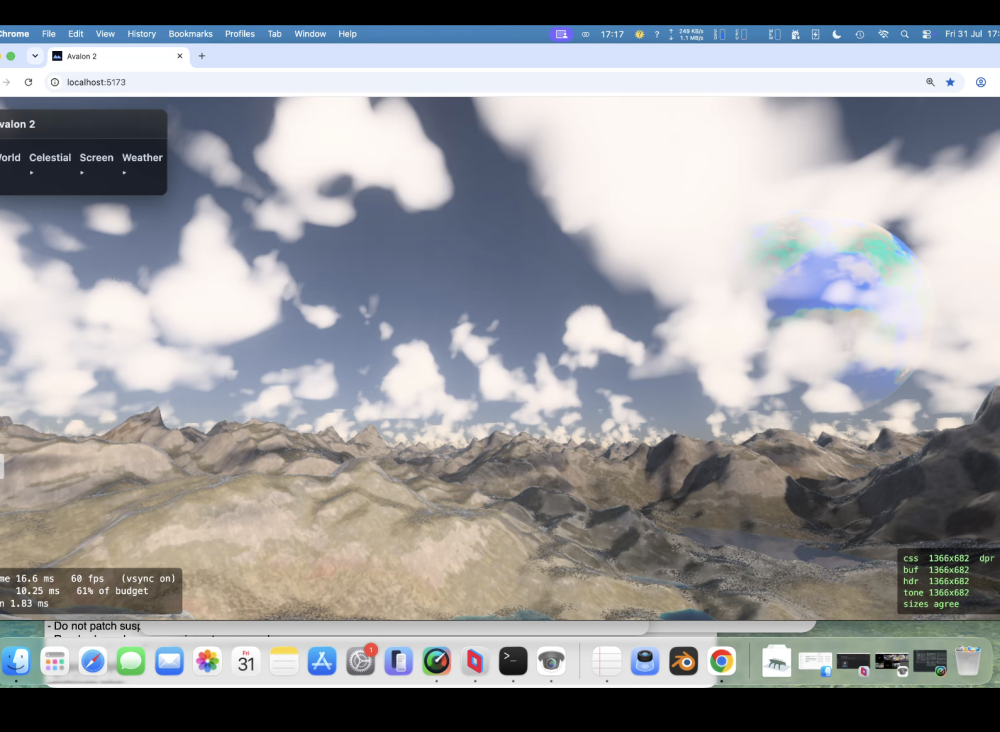
-
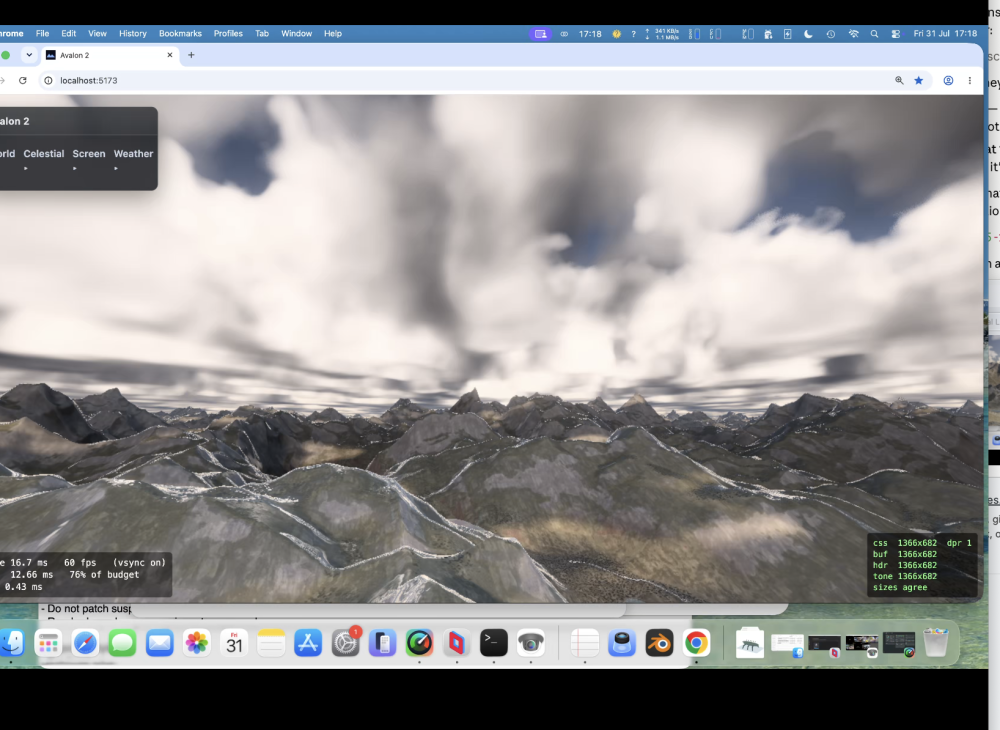
Taken all day to get right ; Claude wants to quit many times! Heavy rain actually runs down slopes! Looks fantastic. I dont think even the might Unreal Engine does this.
-
10% gpu; yep!. 25% if you get the worst possible grazing angle over water. Added upscale (for some minor quality loss) even on the water grazing angle if I drop to 70% gpu at 13%, drop to 50%, gpu 10% Plenty of engine for more fun!
-
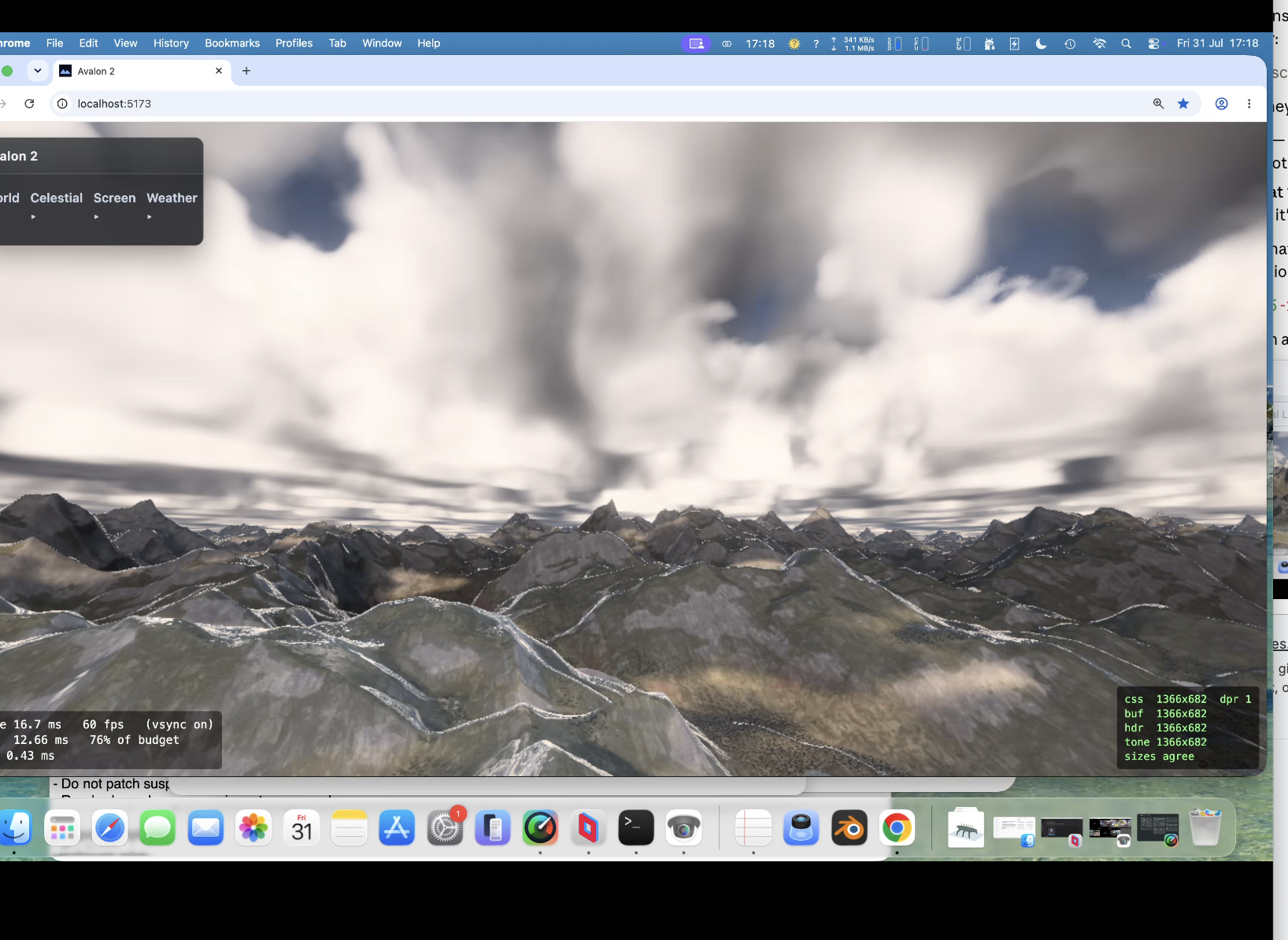
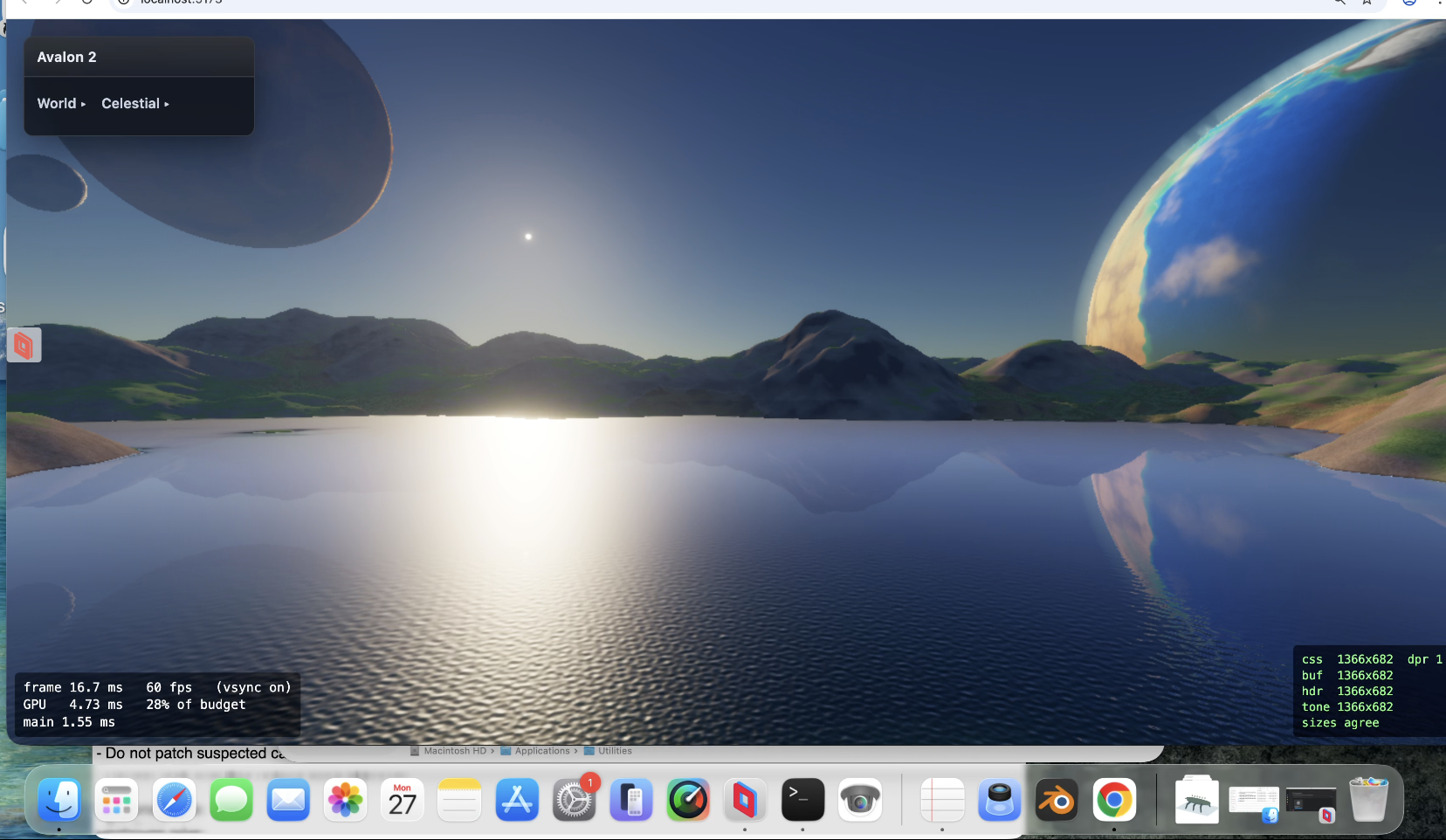
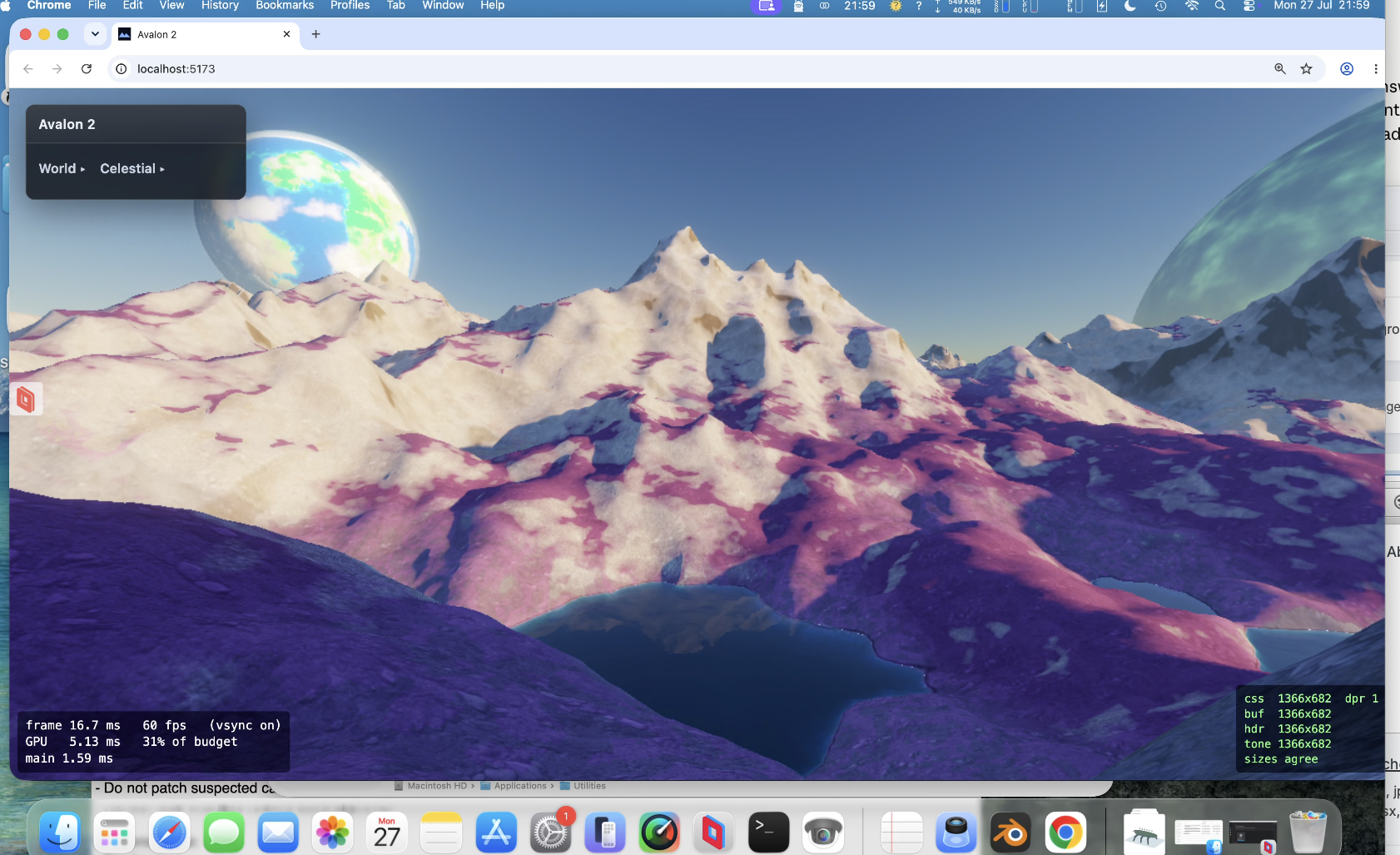
Hit 50% gpu with procedural background planets/nebula/stars. So optimise , optimise, optimise. Took a while now back at around 30% gpu. Proper (frustrating) exposure aswell. So when you look at something really bright you are blinded for a bit and colour 'seaps' back in. Trying to function like an eye rather than a camera (so binned lens flare). Going for clouds again (3rd attempt) - tricky one but got a 25 page spec for it. Then more fun... always bugged me with a height map that of course you cant have arches/overhangs/caves but have another spec for a hybrid system that allows such things. Another sped up thing was that the baking was taking upto 4 seconds (which bugs me) ; down to 1 second now. So startup is far quicker.
-
I'm not building houses any more Uncle Nick - I'm building worlds!
-
Horrific bugs I'd never had found. Absolute bitches - well above my pay grade. But.....better than my holiday snaps!
-
Claude not being so good today. Causing more problems than it fixes. Adding and removing without my knowledge...
-
gpu at 50% thats with a grazing angle view (worse case for ray march) , water on screen, bloom. So a best case of a worst case. So optimise time. I reckon I can get that 50% down to 25% by pre-baking as much as possible in the terrain that gives a noticeable gain. 320Mb about to be burnt (insane when you think about it just how much 320Mb is , nowadays viewed as nothing)
-
No one and I mean no one fully understands quaternion maths … it’s magic maths !
-
I do. Sometimes it's wrong. But trust me accuracy is paramount to realism - I'm on it! You've got bedtime reading of Beer-Lambert and quaternion maths. You wont like either of those trust me!
-
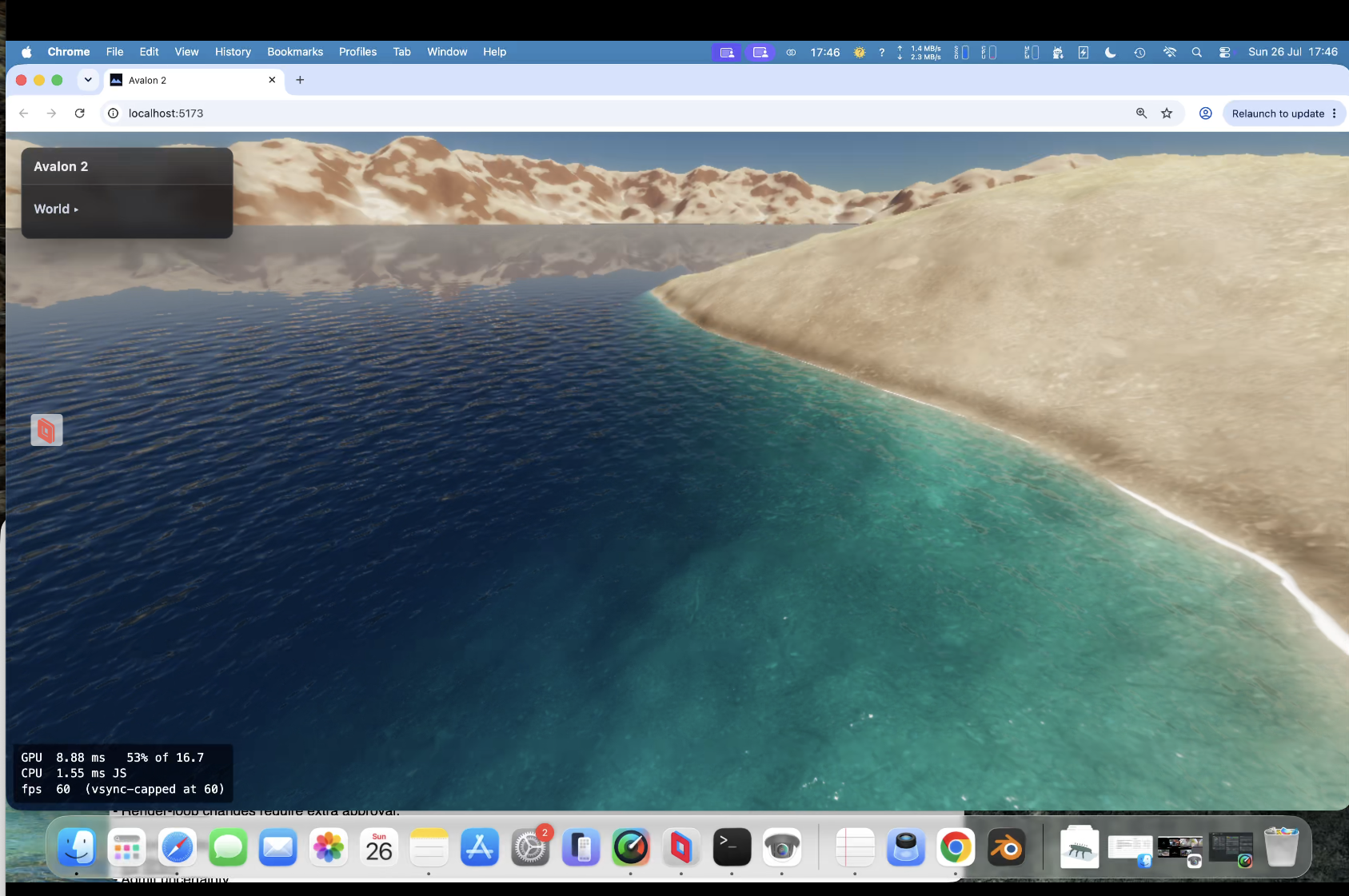
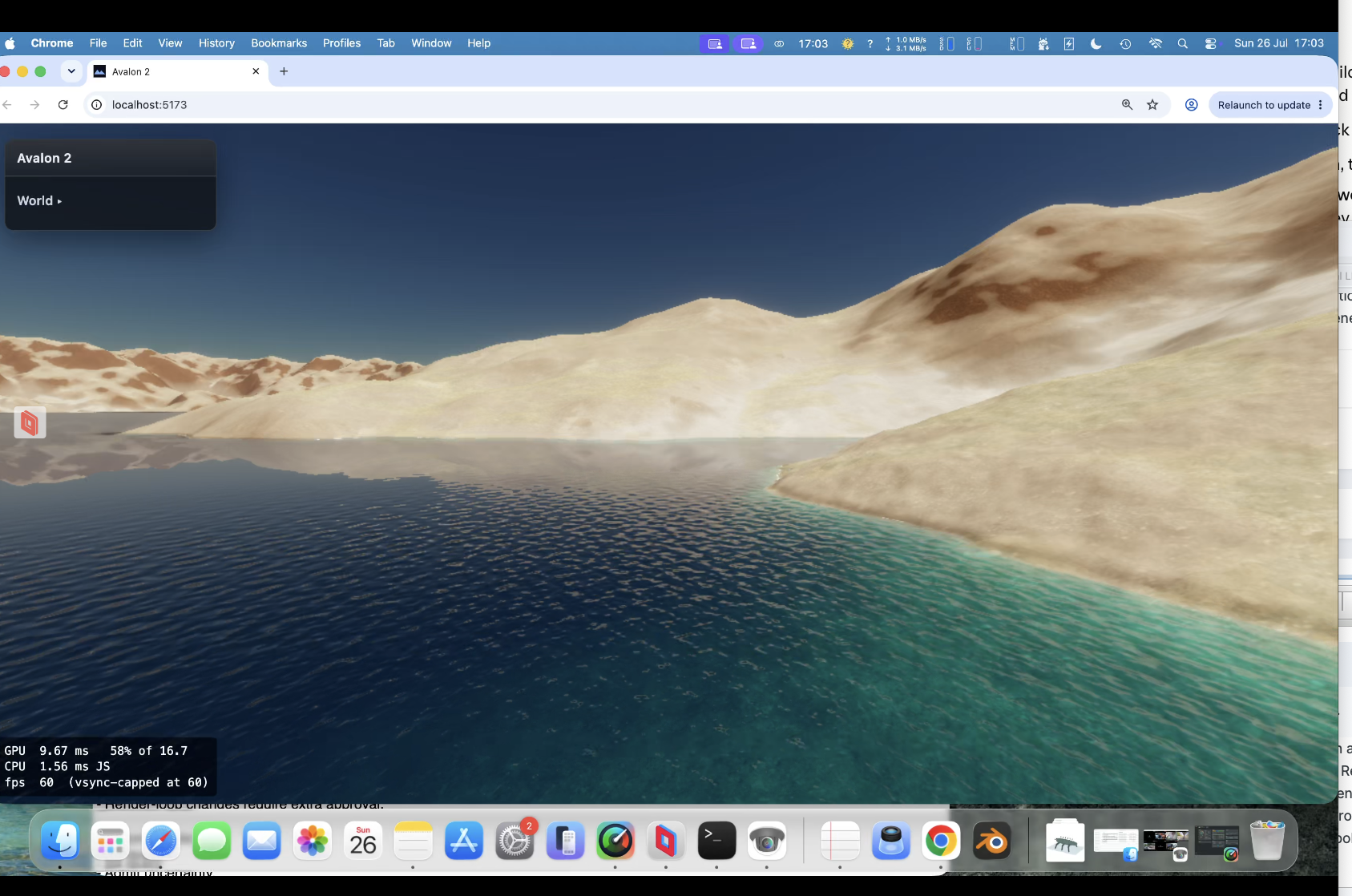
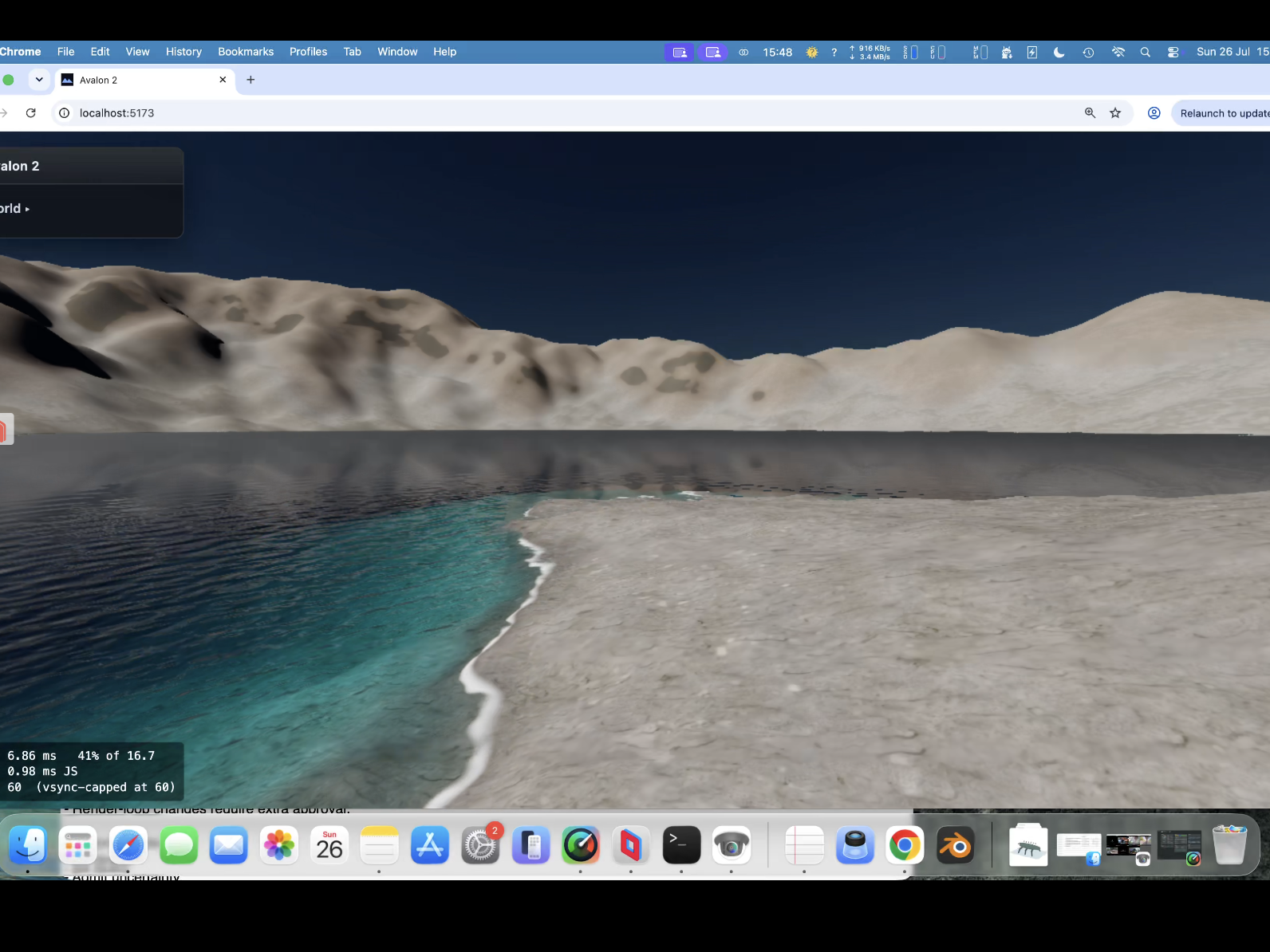
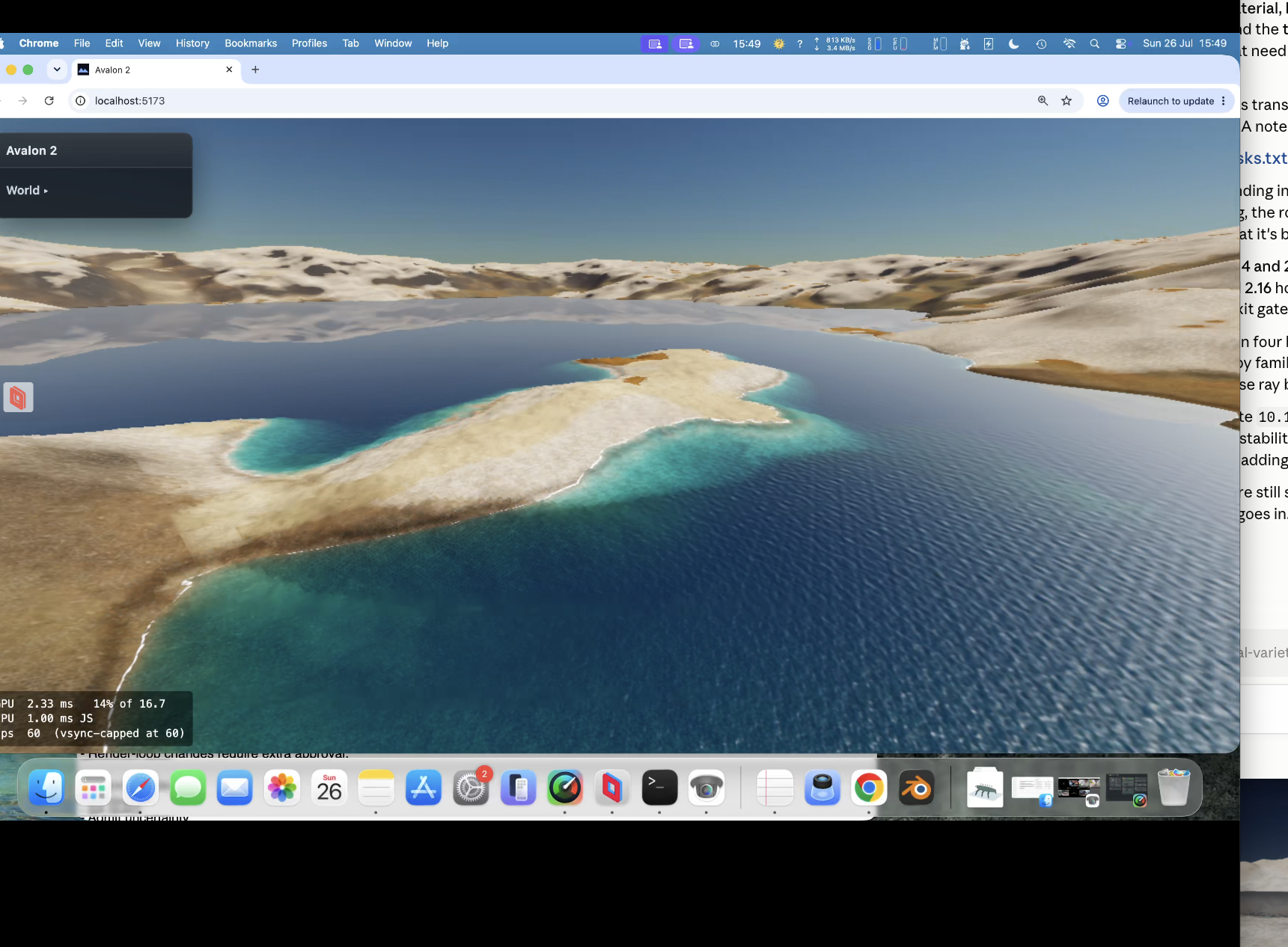
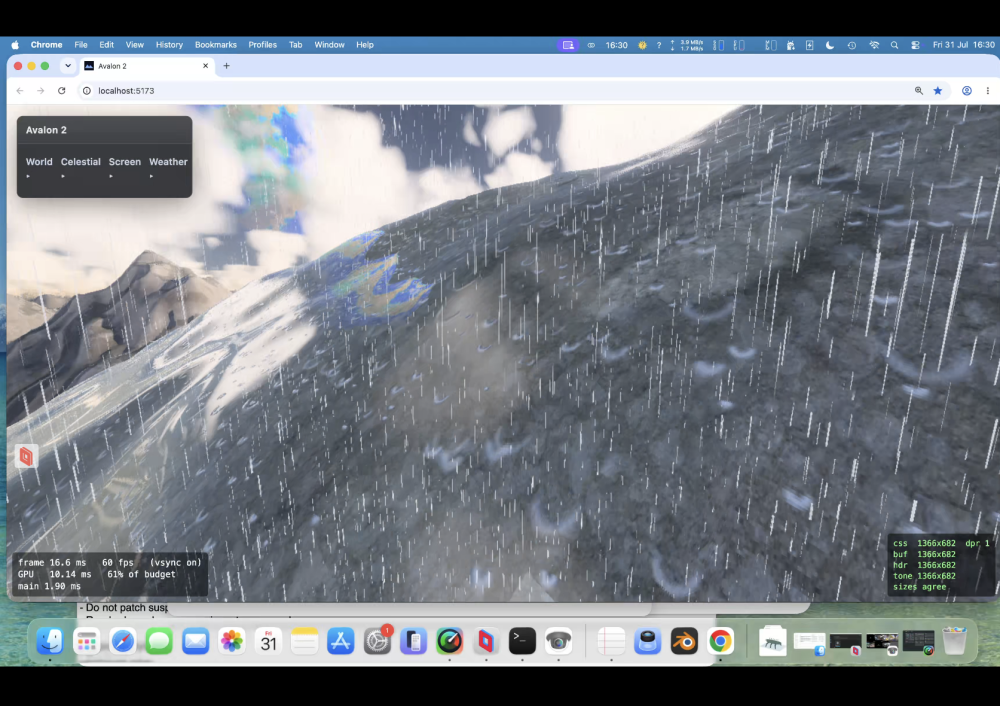
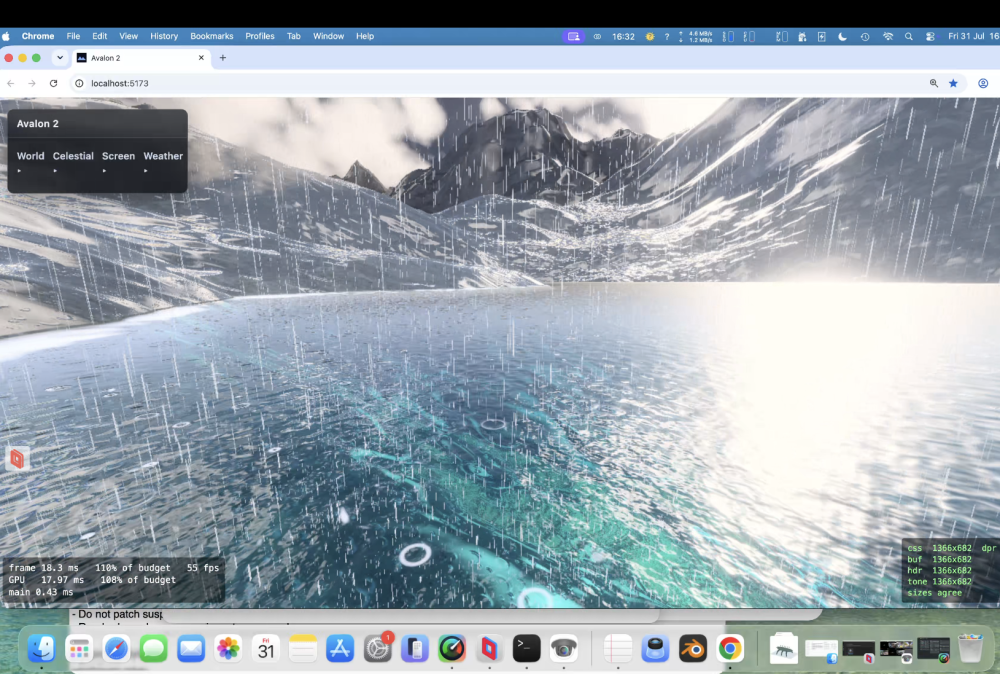
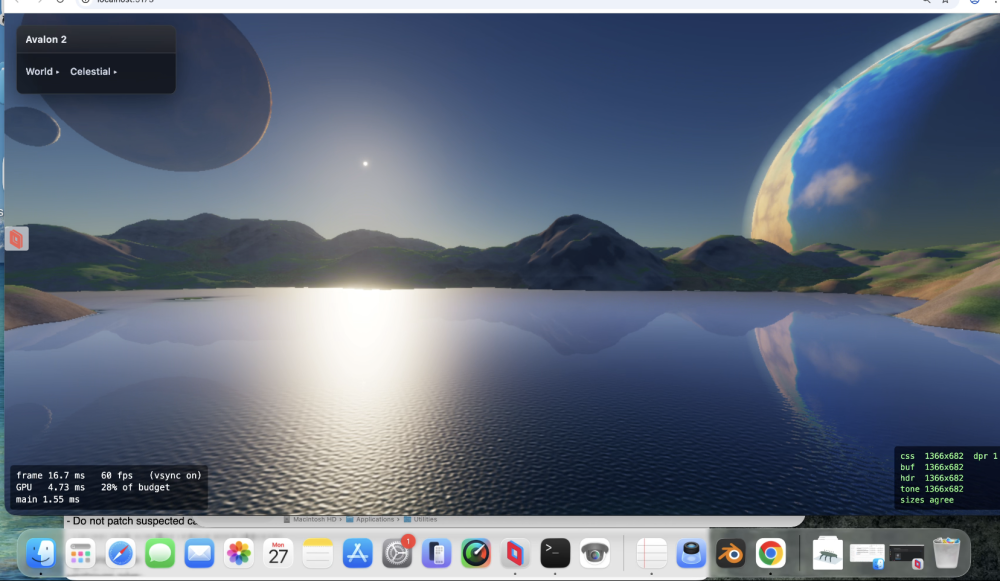
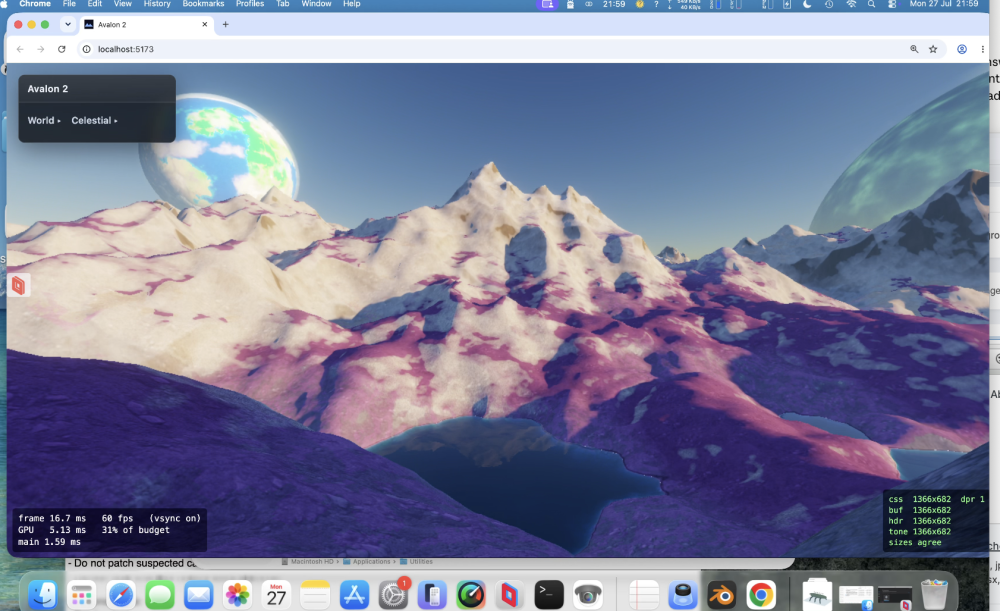
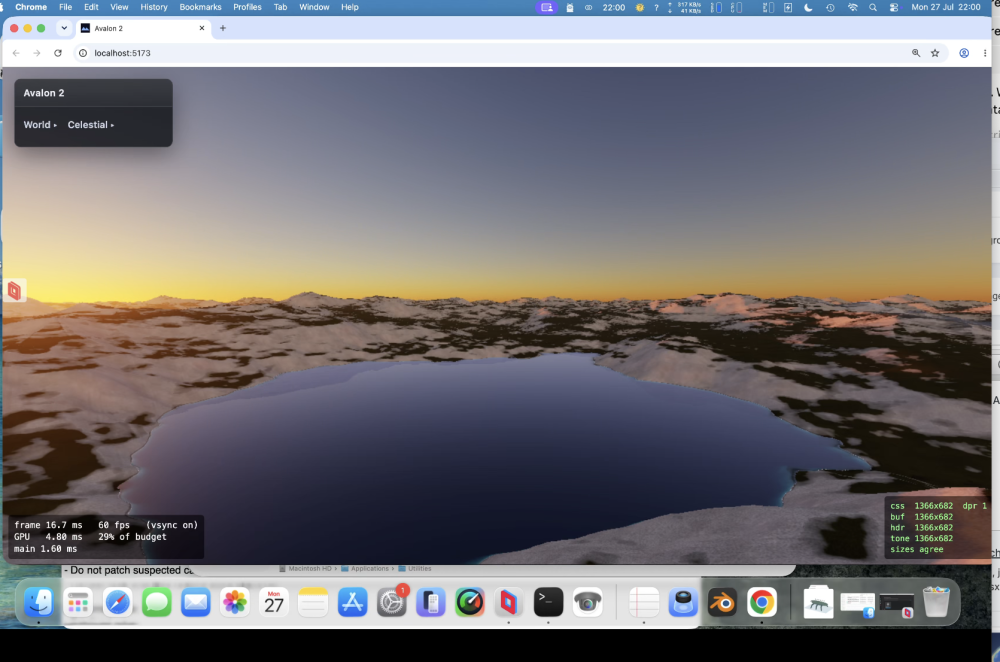
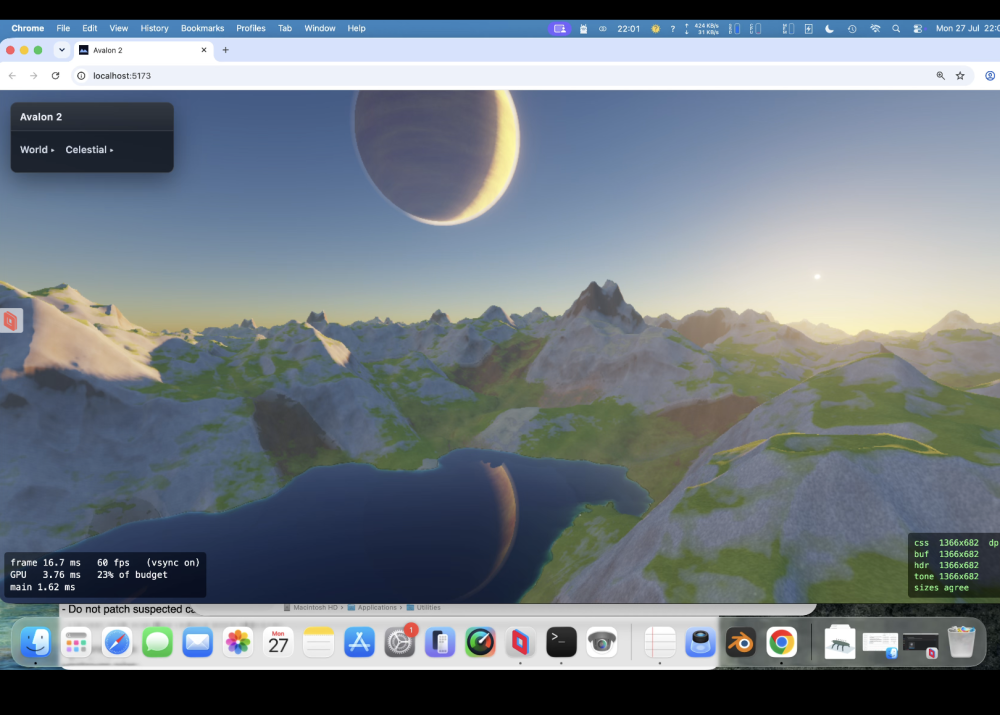
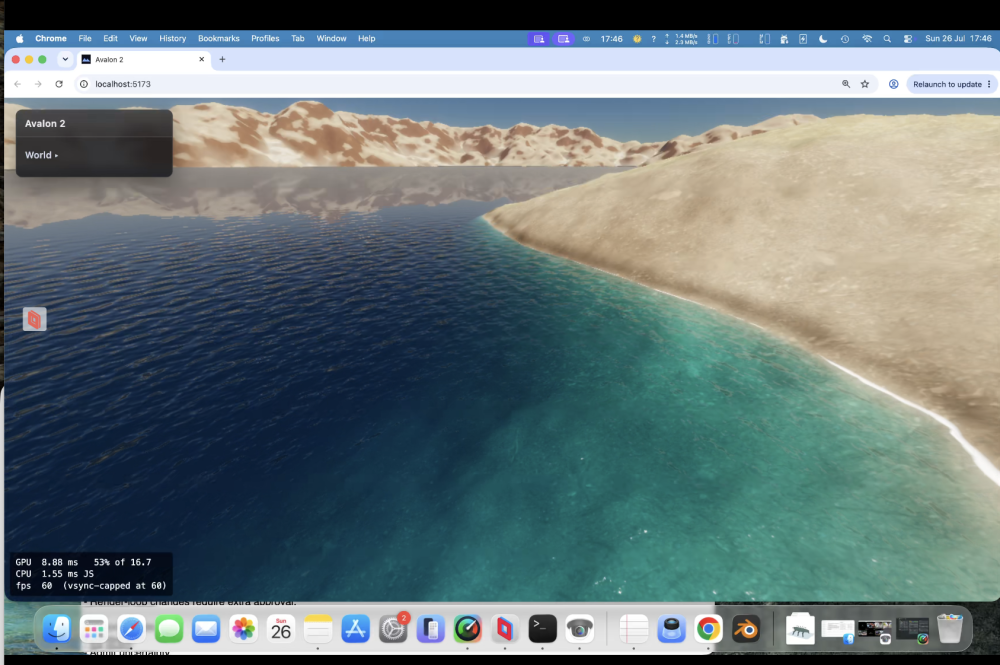
Te-he! As I said water looks different from different angles. So near us (the camera) you see the turquoise and seabed further you would not at this angle; i.e. you cant see the nice blue because our angle is so low - we are looking over it. If I pulled the camera up into the air and looked down at that spot it's there. So looking at water and looking across water are very different views - it's something through the previous 5 versions (oh my!) I just couldn't get correct. look at piccy 1; water we are near is 'clear' (depends on a LOT of maths, sun angle, sea bed, refraction, specular etc etc etc etc ), but look across at the mountains, a reflection and is dark. Beer-lambert (remember you started this science/maths argument! 🙂 ). But I'll let my mate Claude answer.... " The blue stops because of viewing angle, not shadow. What you're seeing as turquoise is light that passed through the surface, reflected off sunlit sand, and came back out — and how much survives depends on how far it travelled through water, not how deep the water is. Directly in front of the camera you're looking down into it, so a metre of depth costs about two metres of travel and the sand shows through. Along the beach receding to the right you're looking almost flat across the surface, and the same metre of depth costs a hundred times more travel. Nothing survives that, so it goes dark. That much is real: at grazing angles you genuinely do stop seeing into water, and a photo taken from that low across a lake shows a mirror at the far shore rather than turquoise. Where ours overdoes it is that the surface doesn't yet bend the view ray. Refraction puts a hard ceiling on the underwater path — about 1.5× the depth, from any viewpoint — so real shallows stay bright the whole length of a beach. Without that ceiling the path grows without limit as the view flattens, and the band dies far earlier than it should. Separately, what replaces it should be a bright mirror of the horizon sky; ours fades reflections to black near horizontal, which is why that stretch reads dark instead of silver."
-
All the things as an ex games programmer I notice and hate. But with finite compute and finite ram compromises must be made. Give me and my new best friend Claude (I've not even sworn at it yet! , honestly not once! , whilst CHAT , well (expletive deleted) me ... I couldn't stop swearing ). The point you made is valid "looks wrong, but not sure why" - I do that a lot. I have to explain what IS wrong - usually in a technical term. So you find things visually 'wrong' thats fine. I just grabbed some random screenshots tbh .
-
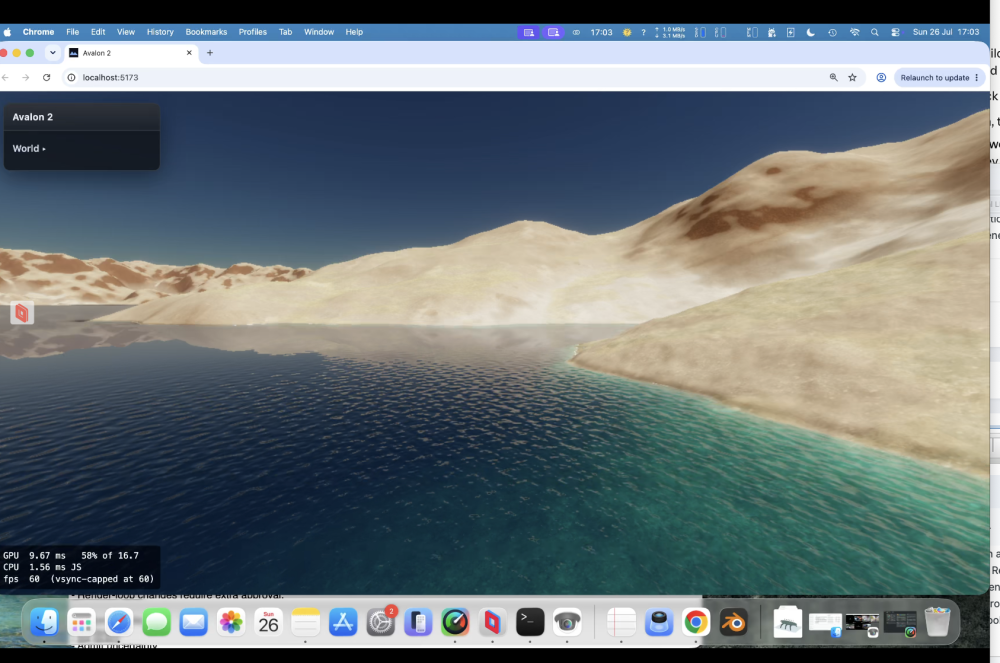
I'll do a video at some point. Water from a certain angle with certain lighting looks 100% convincing. Static's can't show that. Regarding your 2nd comment - not sure exactly what you mean and again depends on camera angle. What's the dogs here is zero lod, zero geo morphing, zero z shadow fighting. So terrain no matter how far you can see looks the bollocks. Focus on 1 peak in the distance - move towards it; perfect!. Also remember Work In Progress!__dbg.marcher.u.waveEarlyExit.value = 0
-
Yeah the waves do have a mathematical view. Easy to see when static, less so when moving. Procedural generation will do that!.
-
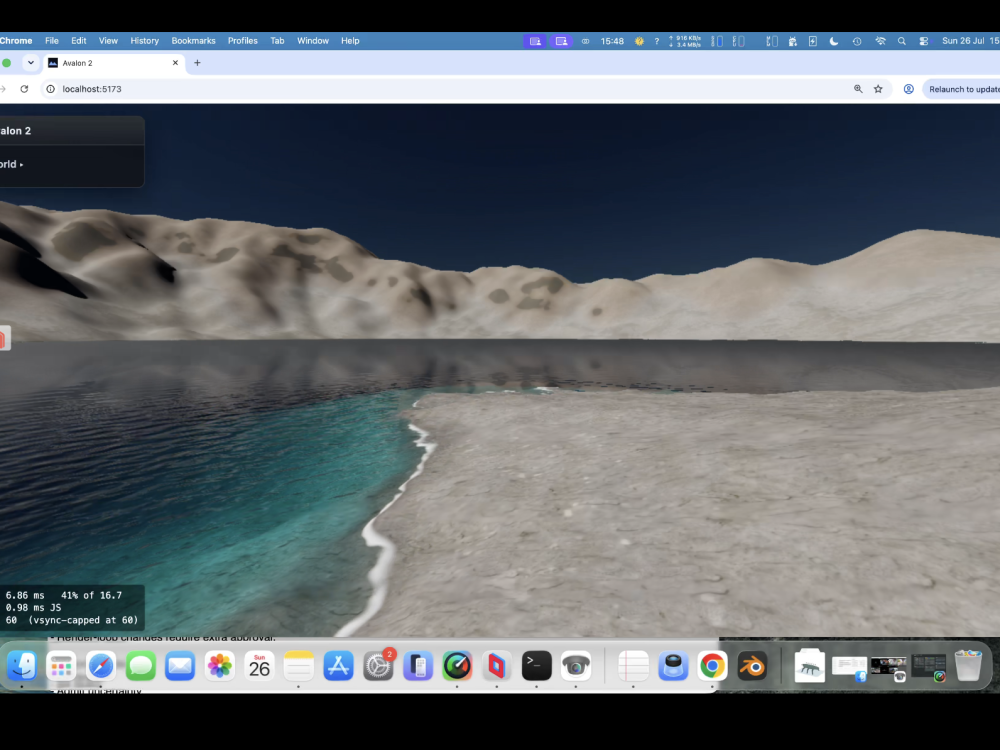
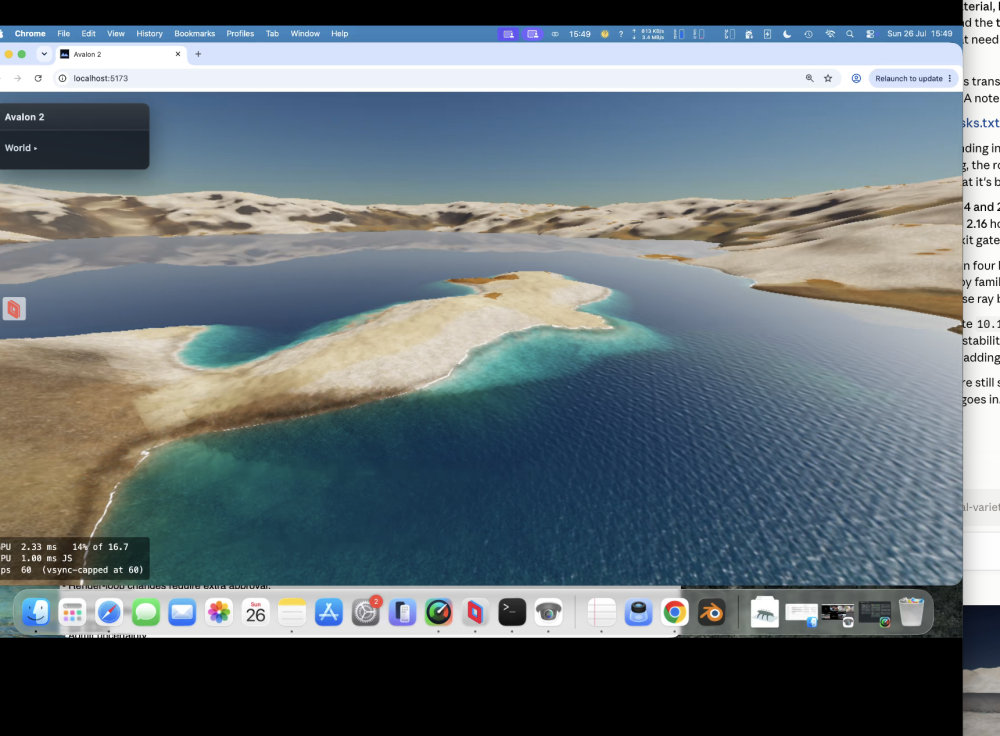
water now is staggeringly good! Proper beer/lamb for depth, waves, lapping, water's a bugger because the same water looks different depending on your view. Look at your feet see the seabed, look across it and it can be almost dark. Managed to get that working successfully.
-
Been a slog. Up'd opus 5 to max (no idea if that truly benefitted tbh). Perseverance pays off with these things though. Near photo realistic landscapes now - eclipses previous effort by some margin. But nothing to show yet until we beat my personal PITA ..... WATER. Such a difficult thing to get right; always a compromise on visuals against performance. Usually looks cheap or just too "gamey". So like the terrain we are going for realism. To achieve that I decided we need to model how/why/where volumes of water form. My logic being if its physically correct then we are half way to it looking correct. Usually these things are cheats like most 'effects'. So we use what we have plenty of... ram. For shadows for example to save a few computes per pixel the entire landscape shadow map is pre computed (around 8gb) - it can be optimised later size wise. Doing just this knocked 5% of render time. I can think of similar such tricks for water.
-
Been bugging me for a while. Whilst the terrain is good it's not good enough (for me). REALLY want to ray march , notoriously difficult and gpu expensive. Doing ok ish. But we have no cliffs, valleys etc - because erosion makes them. So we need to simulate erosion accelerated and 'carve' through the landscape. Decided to compromise with realtime procedural infinite world and go finite (but loops), still procedurally generated of course. Trying Opus 5 as yesterday with 4.8 all attempts at erosion and looking realistic failed. Changed from webgl to webgpu aswell - means everything previous is no compatible. So a big re-write is due at some point. But this is difficult. Everytime we attempt erosion we get some weird mess on a world (doesn't take many spins at random to find one). So I've set Claude up to render them itself, do a top down view and not talk to me until its gone through 50 seeds (pre determined for testing) and 50 random and they all look realistic. Either it will do it or I'll run out of tokens!
-
Claude just told me to open a new session so it can do the job I need better. LOL! So I'm doing that. Finally got to procedural plants - and yes as expected its hard going. If we aren't killing the frame rate we've got popping or visual "that looks crap" e.g. shadows, shadows not moving, imposters, snapping, difficult to juggle and keep fps acceptable.
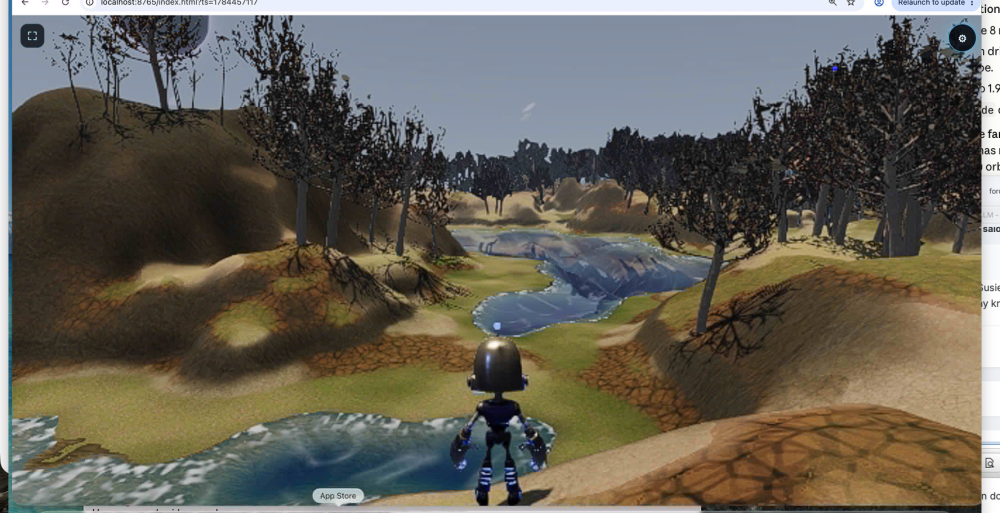
-
Always time for playtime!
-
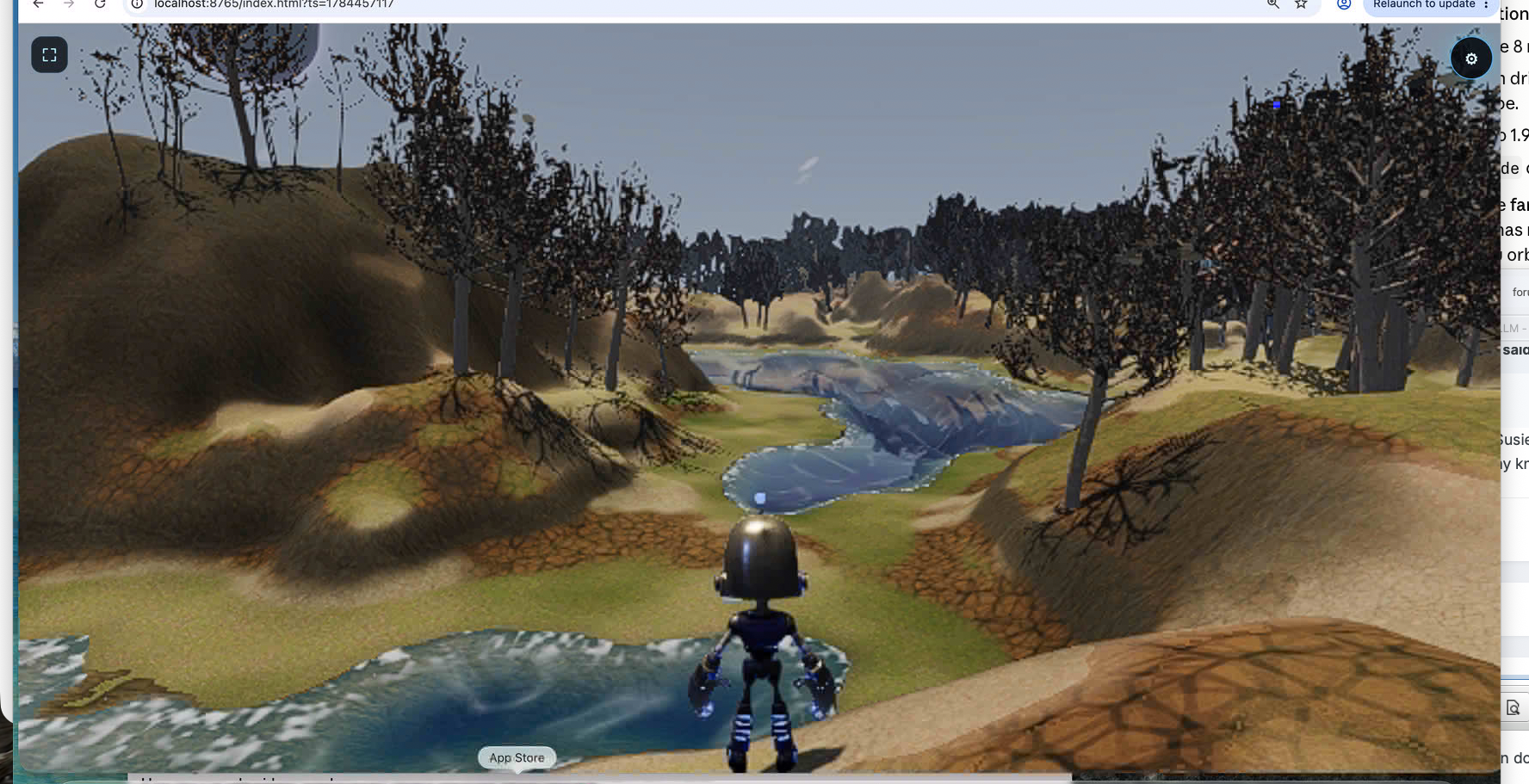
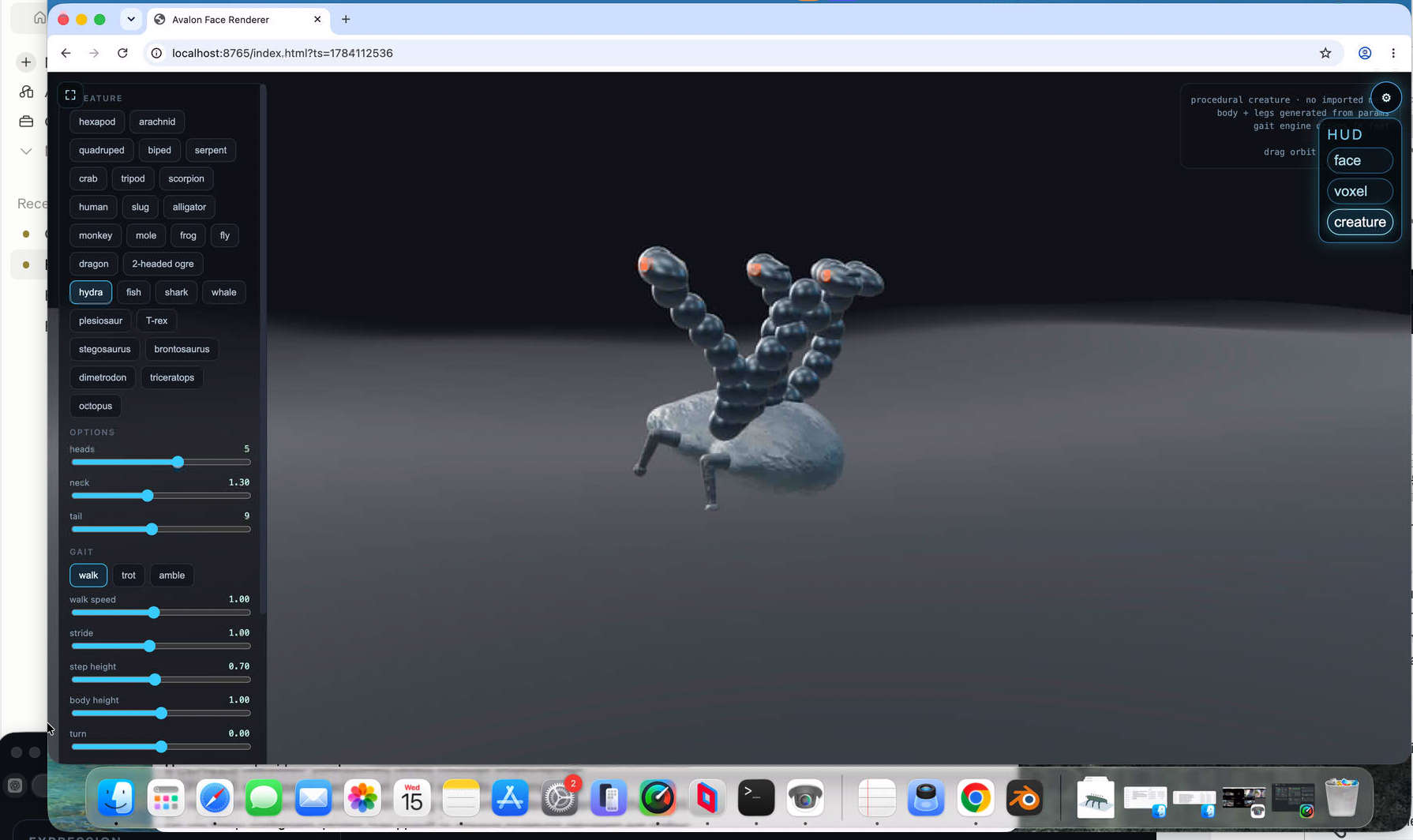
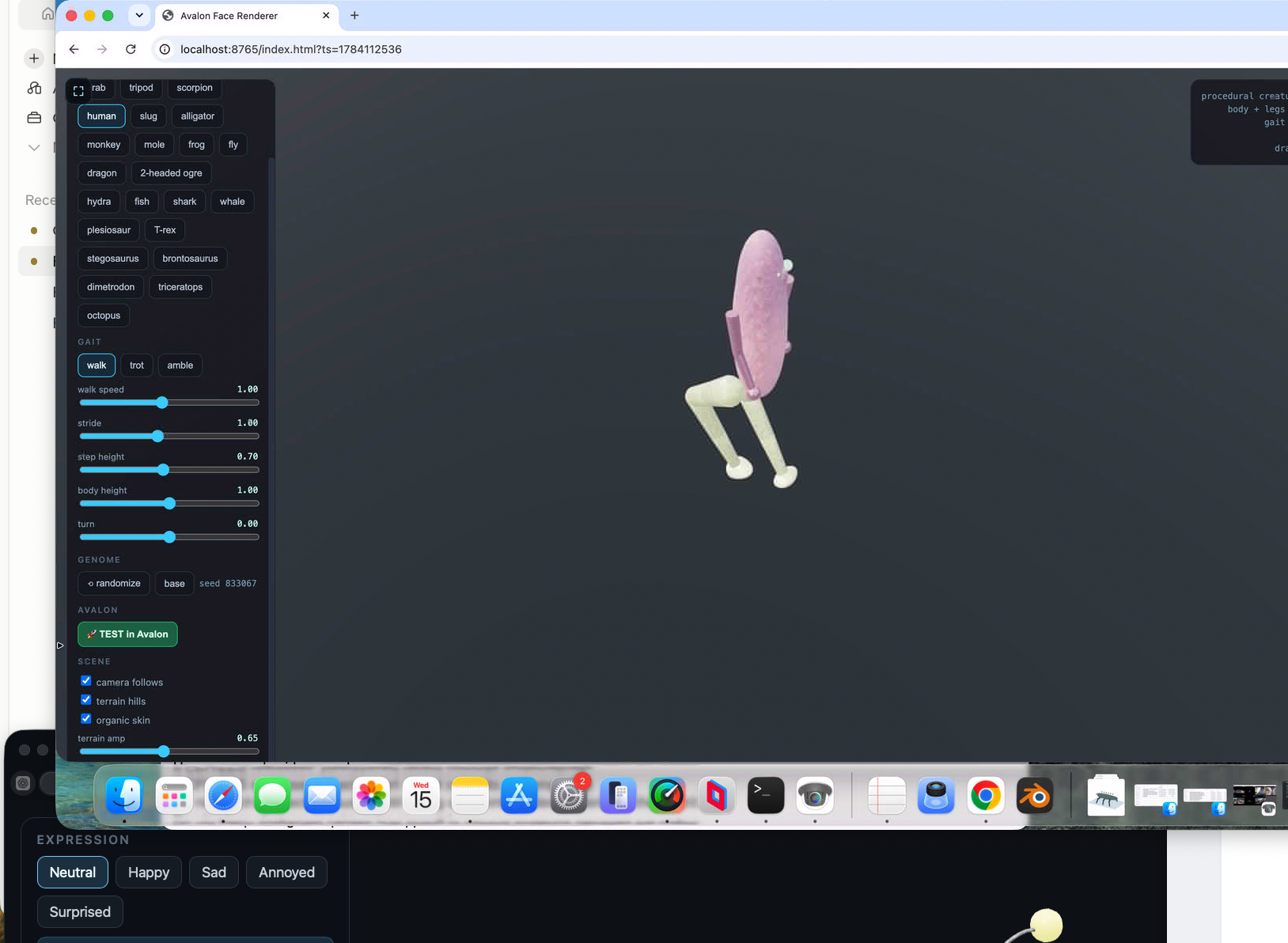
I will get to procedural vegetation honest. Had a sphere to drive over terrain working i.e. physics remap as you move so effectively infinite also. But the sphere bugged me. Trying to procedurally generate something decent was always poor - like the original face attempt. So, bought a rigged and animated model to use! But also I got excited about procedurally generated creatures so invented creature lab! - some quite funny!, needing work of course. But AMAZING!


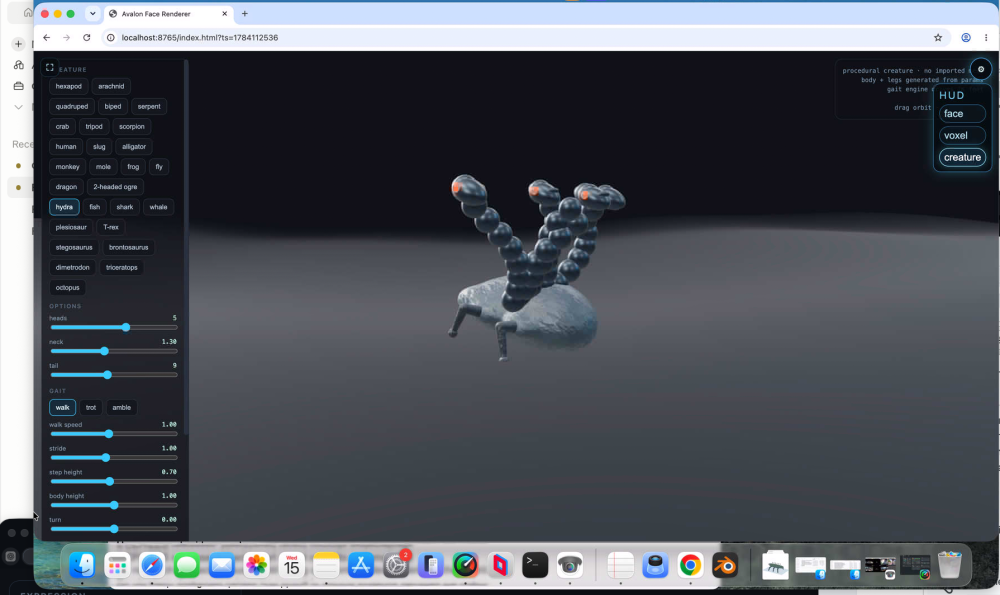
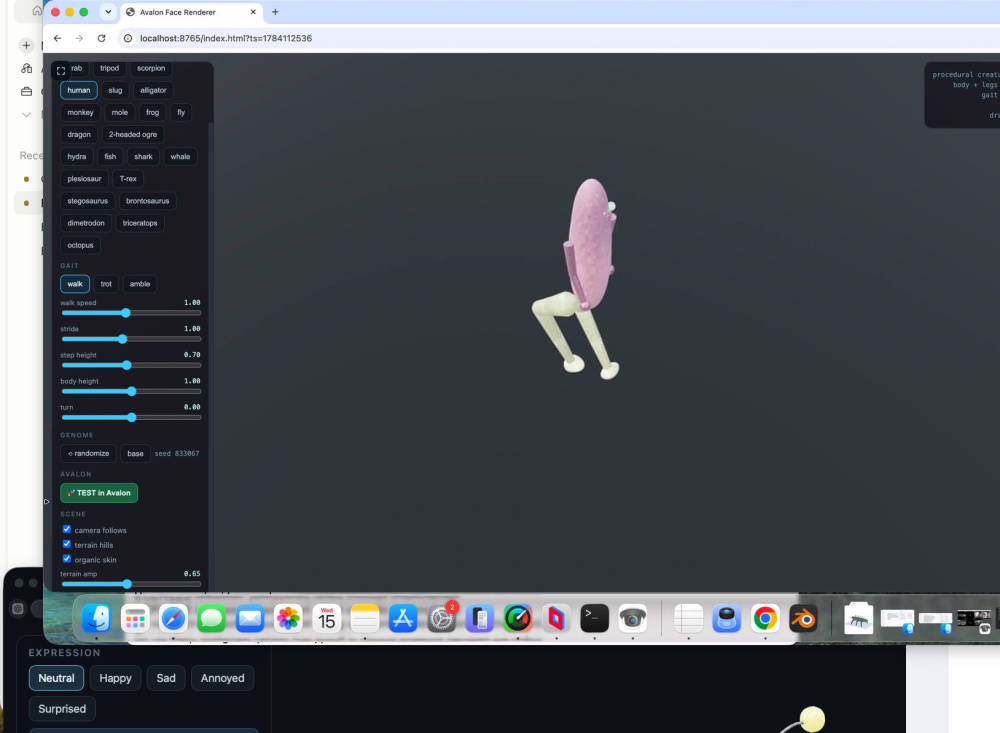
-
5 hours on 1 bug. Claude constantly wants to give up. Lots of horrible maths (well beyond mine and most people's comprehension). A function needs to be computed and the exact same code is done in ALU and in shader. 100% same code. Therefore assume same output. True - mostly..... occasionally a minute fractional variation between the 2 compute functions. In a sane world wouldn't matter; in procedural generation after a zillion iterations big difference. Claude and I were guessing and trying to reason everything between us we could think of. So I got claude to call the 2 functions with the same values accumulating millions of times. Different results proved it. So we engineer everything now that the compute is done only by one thing and a separate method for everything else to read it. Slightly slower method but works! Also means of course that the procedural worlds I look at (always use 42 as my base case) , everyone of the 16 billion are now different LOL!
-
Nice!

-
getting there

-
It struggled with the sci fi picture. Why?; because it doesn't follow proper building design!. Staircases not going to all levels, cutting through floors, ending incorrectly, no steps etc etc. (expletive deleted) me I had to basically build not just a underground house but an underwater one to get it happy!.

-
The number of times I argue this whether Claude ot Chat. What I want against what I get!. LOL! . BBC BASIC anyone?. Anyway I map out a mega spec and unlike Chat Claude will deliver something more inspiring!. Compute_cheap_to_pocster=TRUE; me thinks!