Pocster
-
Posts
14367 -
Joined
-
Last visited
-
Days Won
29
Everything posted by Pocster
-
Tried that.
-
Someone lazy in our household left concrete blocks on the decking for some considerable time . On removing them get these white marks . Tried cleaning them with various things but won’t budge . This permanent or can be removed ? Some people ! Buy materials ; leave them for a bit and then cause more work . I don’t know ! Tsh !

-

Vent Axis Sentinel Kinetic
Pocster replied to Pocster's topic in General Self Build & DIY Discussion
Vent axia sending me a new pcb foc 😊 very kind of them -
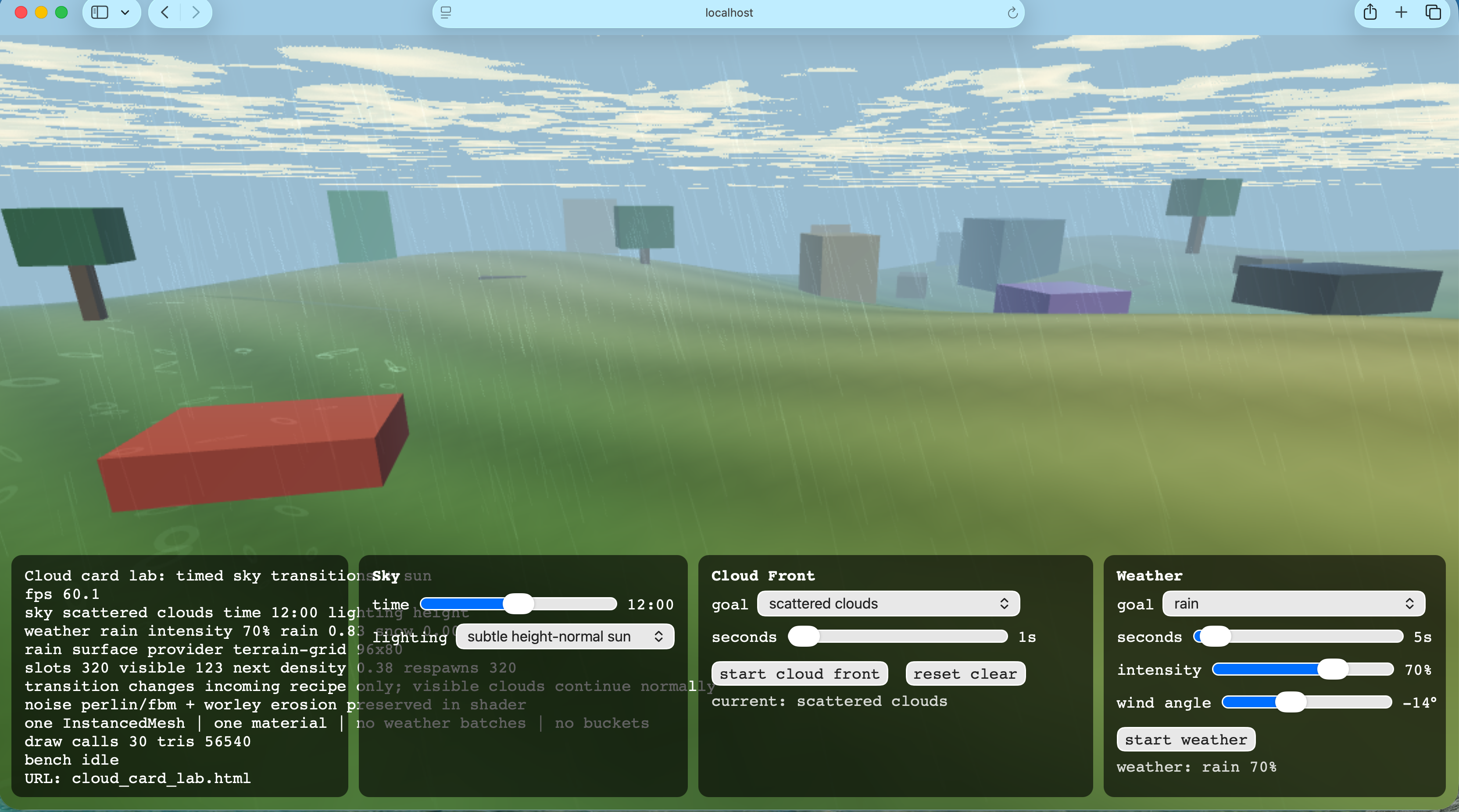
Accusations from chat that I changed the code! Accumulative wetness at very little gpu cost; I like my wetness . This of course is leading to accumulated snow effect

-
Chats been very good today. Weather effects are always a pain because everyone expects them to look good but cost nothing. So we built a weather lab for testing.
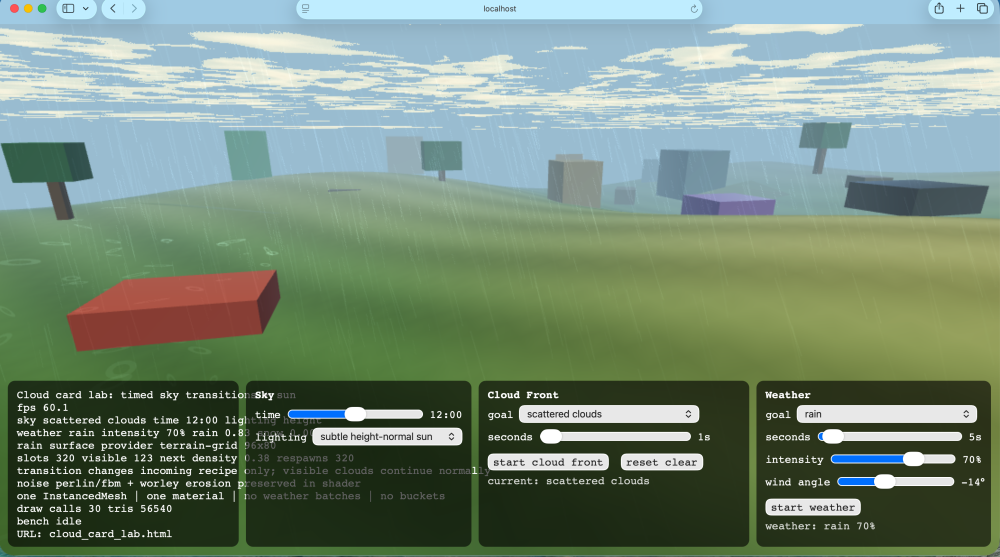
-
Vent Axis Sentinel Kinetic
Pocster replied to Pocster's topic in General Self Build & DIY Discussion
Oi ! Now you’ve given mine a problem! Fan running flat out !!!! -
Big (expletive deleted)ing argument over flowers having shadows....
-
Vent Axis Sentinel Kinetic
Pocster replied to Pocster's topic in General Self Build & DIY Discussion
I'll try! from memory!. Yes its the same for both fans. Get cover off remove reactor core thing unscrew panel around screen. there's a few screws Assuming thats off. each fan has 3 screws I think mounting it to the chassis remove them you then have to unclip the slide out pcb - it was fiddly (probably need to unplug all connection (I labelled mine so I didnt mess up) As it slides forward the fan connectors are typically at the back. Unplug them Then the stupid bit is once you've taken the connector off the end you have to feed it back so that the fan can come out. i.e. the cables are so tight fan as zero play until it gets some cable slack Thats from memory!. if you get stuck please put photo's up to refresh my brain. It's clearly designed so non Axia engineers dont do this! -
I love the way I can optimise by making suggestions to chat. It doesn't "get it" until you suggest it. It was doing real time shadows on every object (even grass) which kills the cpu and gpu. I want shadows on everything but there are lots of 'cheats' that can be done if you know what to ask! Briefly tried this voxel demo on a nuc (this will be the avalon face/voxel screen). Was around 20fps. Go back to chat tell it to inspect and explain how everything is rendered in the main loop. What's cpu bound what's gpu bound. 10 mins later on nuc 60fps with plenty of cpu/gpu to spare.
-
DO IT DO IT DO IT!
-
You need to go three.js .... man stuff 🙂
-
Abuse yields results! River with bed, ripples, refraction. Real shadow volumes. Rocks with proper 'realistic' placement. Wind so canapoies can move. Look at that drawcount 🙂 just 270 ish.
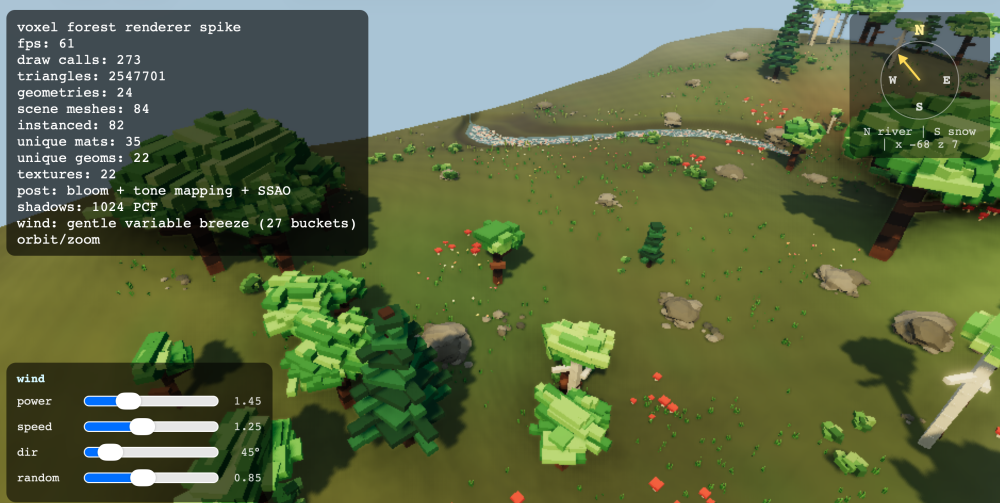
-
common things I tell chat when coding. "Use" when I upload a file. Sometimes it ignores the evidence even though is asked for it. "don't guess" to hopefully avoid blind patches "you a zx spectrum?", "this a bbc c demo?", "does that look like a ps5 effect?" to 'motivate' it And of course lots of abuse. It's so funny. I has repled the obvious "yes thats shit" , but once it said "it is a load of wank"
-
SWMBO made me do some outdoor work! . Anyway welcome back to my youtube channel. Chat not very good at optimising drawcalls. We started with 50k!!!!!. Now down to 1. It needed a word. Struggling with the river at the moment. Hit that subscribe button NOW!

-
Welcome to my BS YouTube channel. Today we are going to create a minecraft inspired game in 10 seconds!. Hit subscribe!, it's you viewers I need! - thanks to our sponsor buildhub.org.uk.

-
But I expect I'll go Minecraft style!

-
All of 2 minutes work! 😀
-
Though cloud tokens arent an issue for me now I use ministral mlx for fast language parse. If its a knowledge question it passes it to qwen. I suspect I'll be passing other stuff around to various models depending on the requirement. I'm having a break from that part and looking at realtime 3d scenery for the backdrop - I like my eye candy!
-
Oh yes!. Well as you know you get good days and bad days! Mines been epic. Massive speed increases. Local llm "whats the capital of france?" working. Current affairs " whats the news?" gives headlines and options verbally if you want more detail. Will add history so you can have a conversation. Gained a further 82ms saving on STT (I know, I know !). Honestly now its so fast to respond to even complex stuff I'm well impressed. Started on timers like Alexa (a SWMBO requirement!). TBH if I coded this by hand that's weeks of work for sure. But of course I never look at the code! G n T time now!
-
Chat has been SO good today I might give it a promotion - nothing to do with me spending 90 quid......
-
Saved another 250ms ... yeah I know. I'll stop now! sad.
-
WOW oh wow! Never really looked into how a LLM generates its output i.e. the cost. Assumed its just generated at the end but it isn't. It's generated as it goes ! So each token passes through the model. Never thought of that! SO! 5 seconds with a moderately complex phrase after json compaction is now 1.3 seconds! BOOM! WHO"S THE MOFO!
-
Really awful bug. Chat 5.5 thinking kept patching and we kept rolling back. I kept trying to think of other ways to deal with it so we can try different approaches. Been at it for 45 minutes. Rolled it back. clicked "pro" gave it all the info I could. Pro then thinking for 14 minutes!. Found a really obscure issue - MAGIC! FIXED!
-
Dont trust any of the AI firms.... Apparently GLM5.2 local is really good - of course hardly anyone can run it ....