Pocster
-
Posts
14391 -
Joined
-
Last visited
-
Days Won
29







Pocster's Achievements
Advanced Member (5/5)
2.5k
Reputation
-
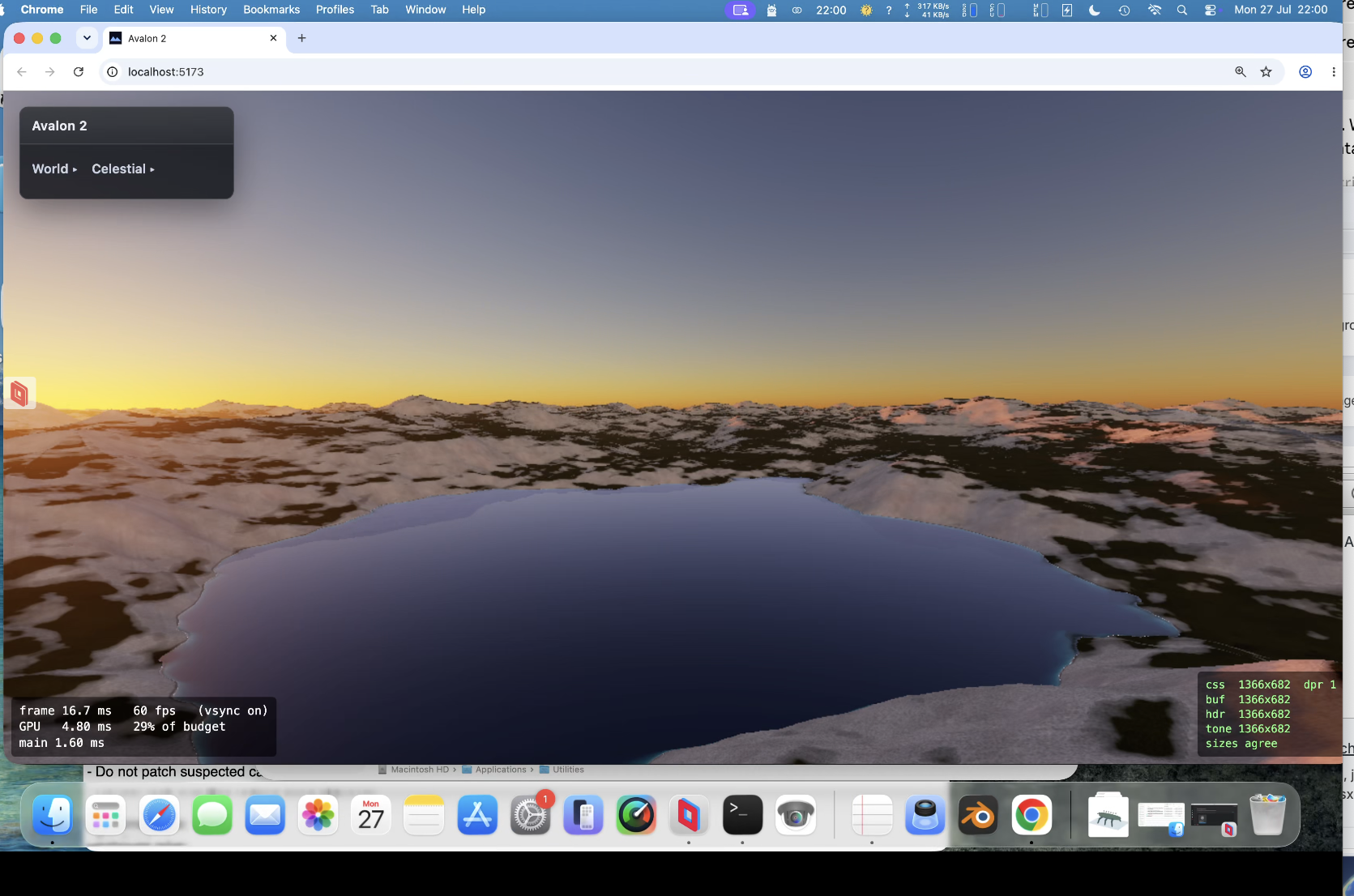
Tell you what - that's a massive understatement. What I mean is I've created a custom 3d engine that would be commercial grade - yet not 1 line of code. That is the real power of AI. I see plenty of youtube/reddit "wrote this in 5 hours with Fable from 1 prompt". Some are believable some are slop. But most are relatively simple (still impressive that Ai can take "write me a really good minecraft game with dinosaurs in it" and still produce something). But use it properly from experience and build it up layer by layer rather than the final product from 1 prompt and its a phenomenal tool. The accomplishment here is WELL beyond my technical ability. But the "difficult" parts the code and horrific maths aren't my burden 99% of the time. I'm still in awe of what's possible. Must also admit it can take some effort - occasionally days on 1 feature to be correct. Or bastard bugs... we had a few mountain tops going black as you approach. No obvious reason some would and some wouldn't. Check all the render stuff/textures/lighting everything me and Claude could think of. Nothing obvious. Found it out of frustration!. The ray march on water can shoot a ray so far that it can hit a mountain top. Essentially at that point its a NaN so plots black! - what a bast!. Water affecting a mountain maybe 4km away in real space. That kind of bug finding without Claude (as I've done many a time when a software engineer) its pure torture and can literally take weeks to find...
-
That was an esp32 project and works!. I'll integrate that into Avalon later. One thing at a time! ( well lots of things at lots of times really - so never get bored!)
-
Theres always ways to optimise. My main lever is of course the shaders (even though Claude wrote them) and pre-baking - 256Gb to burn so we create lots once at runtime to use later and save on some computations. The original premise is still there - just got a bit distracted. But yes the Alex/Chatgpt from Avalon 1 will be imported into this. The robot running over these luscious landscapes will tell you when your chicken is ready and then you're playing Ed Sheeran AGAIN!
-
Amateur ! Time to analyse shaders ! Optimise 💪
-
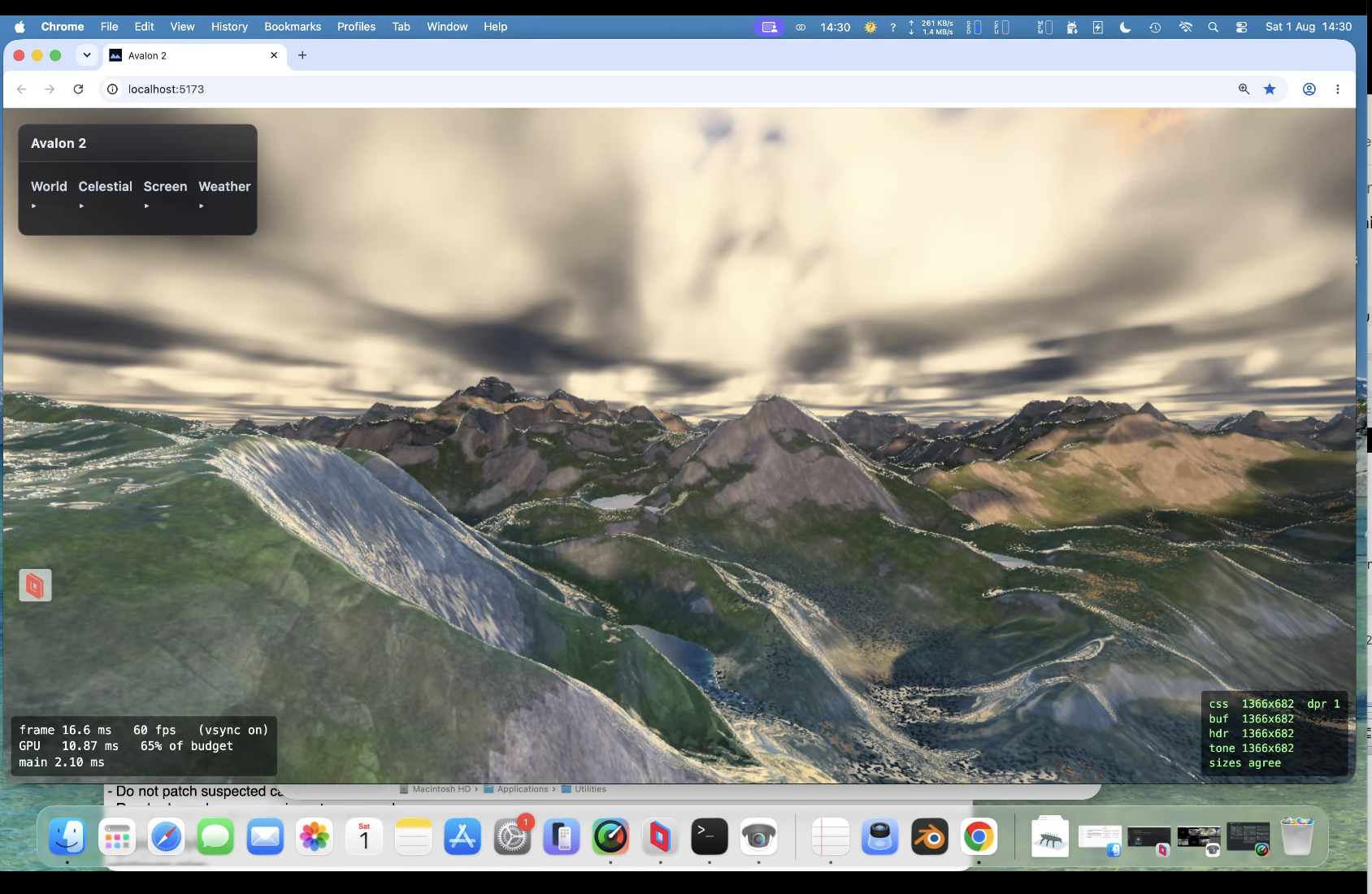
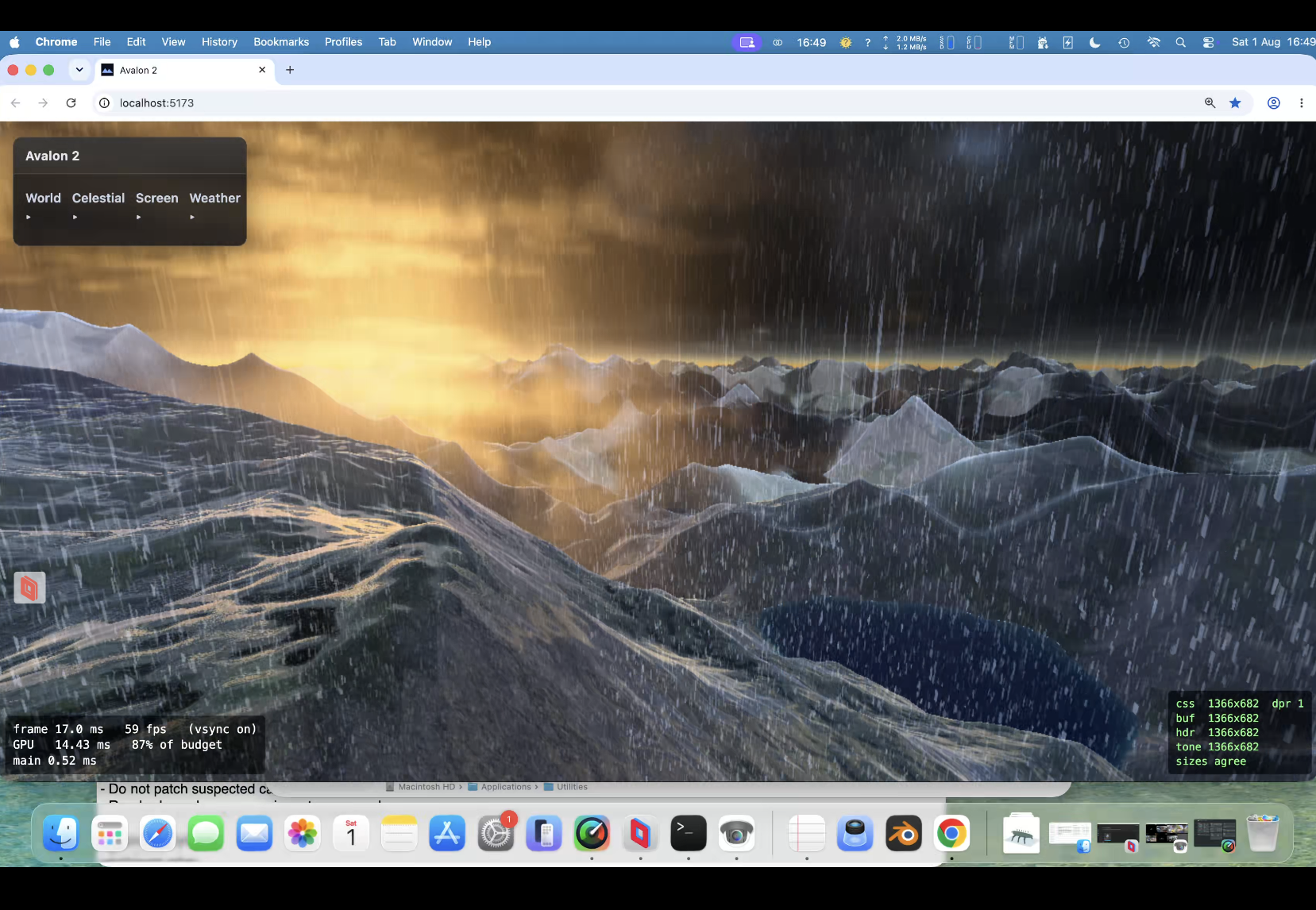
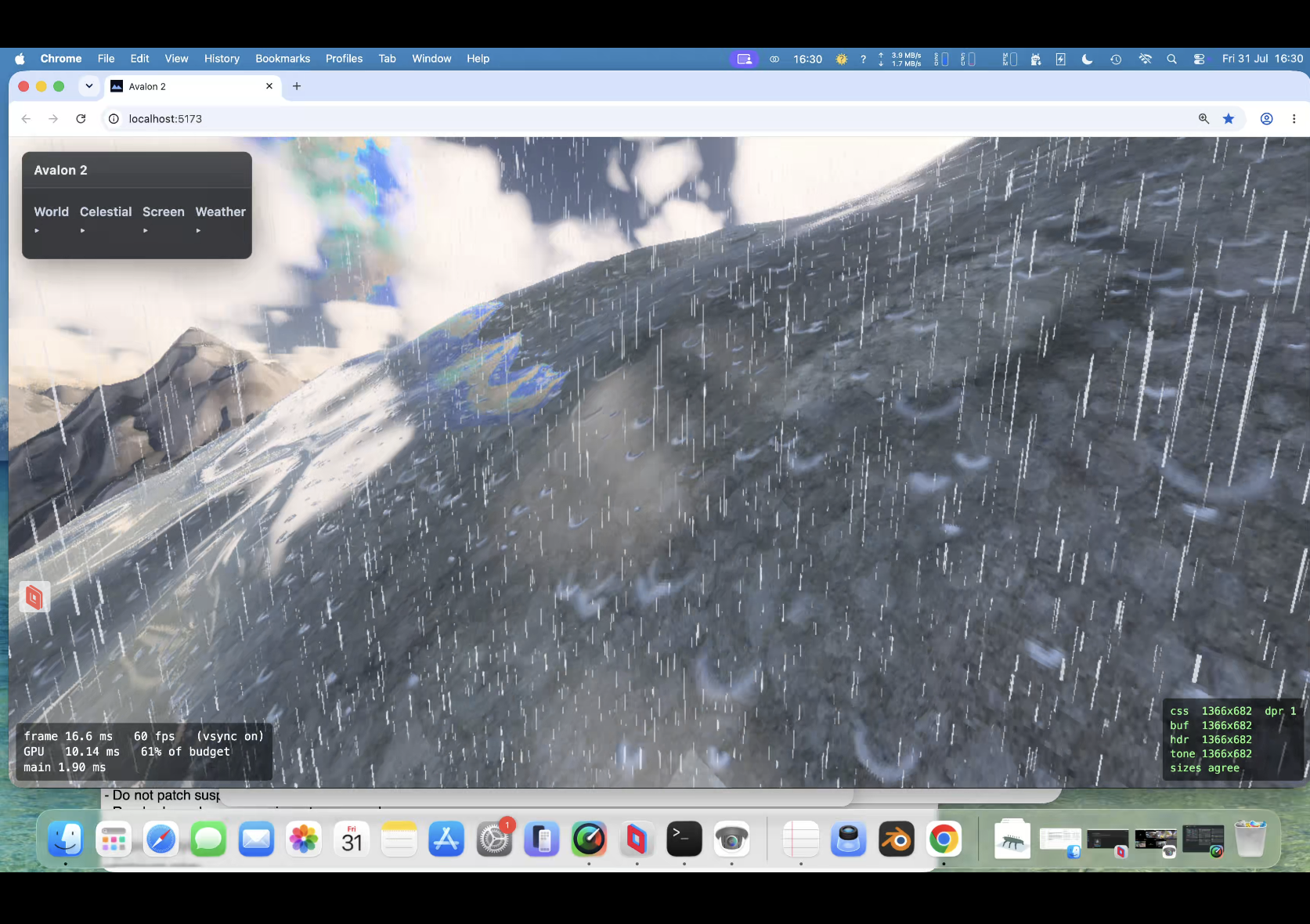
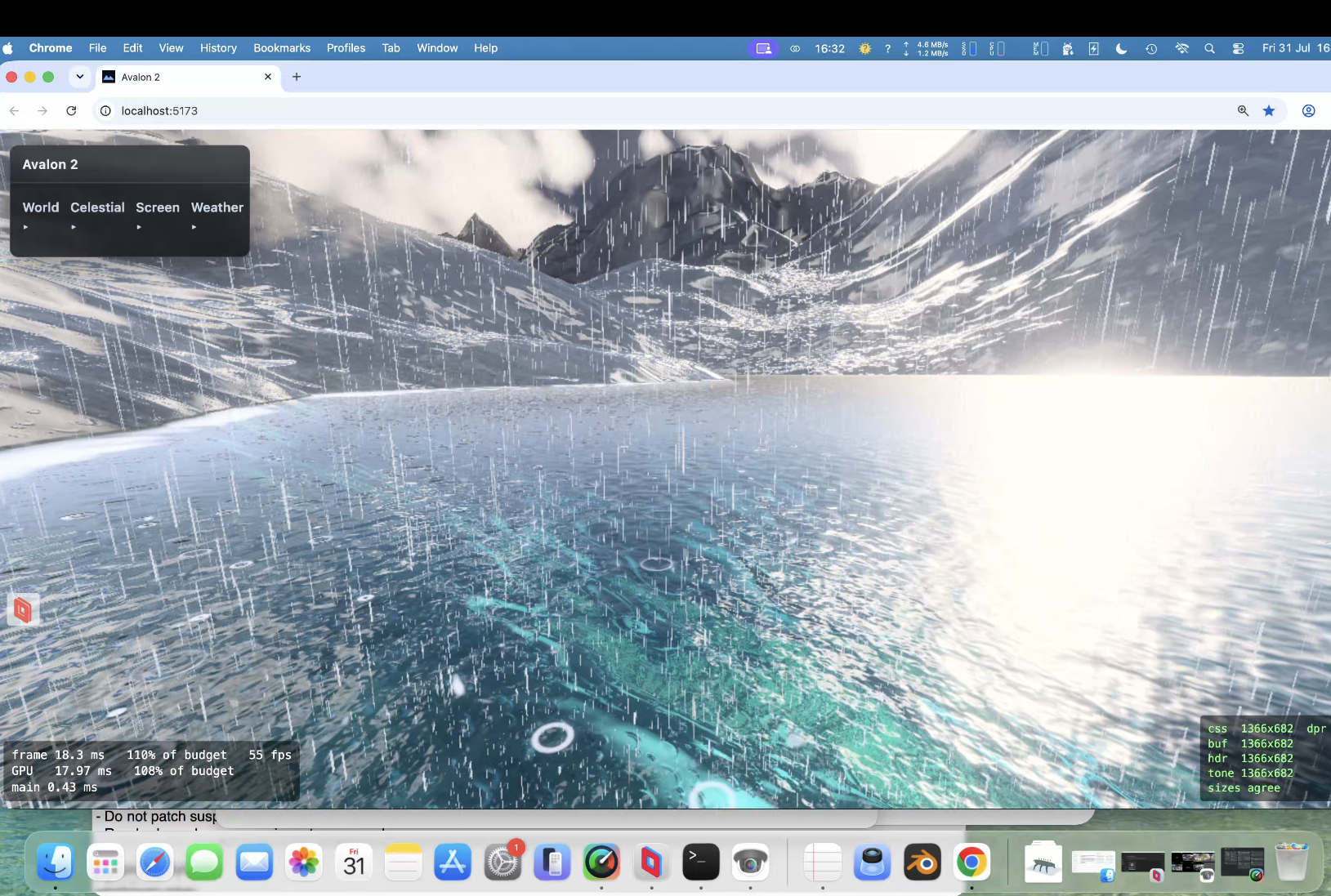
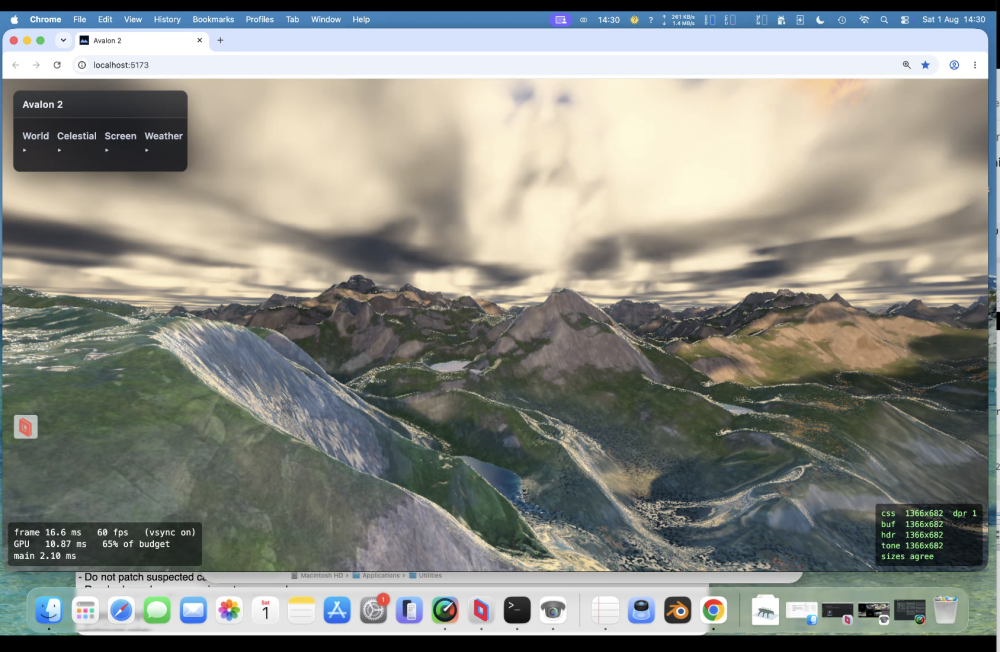
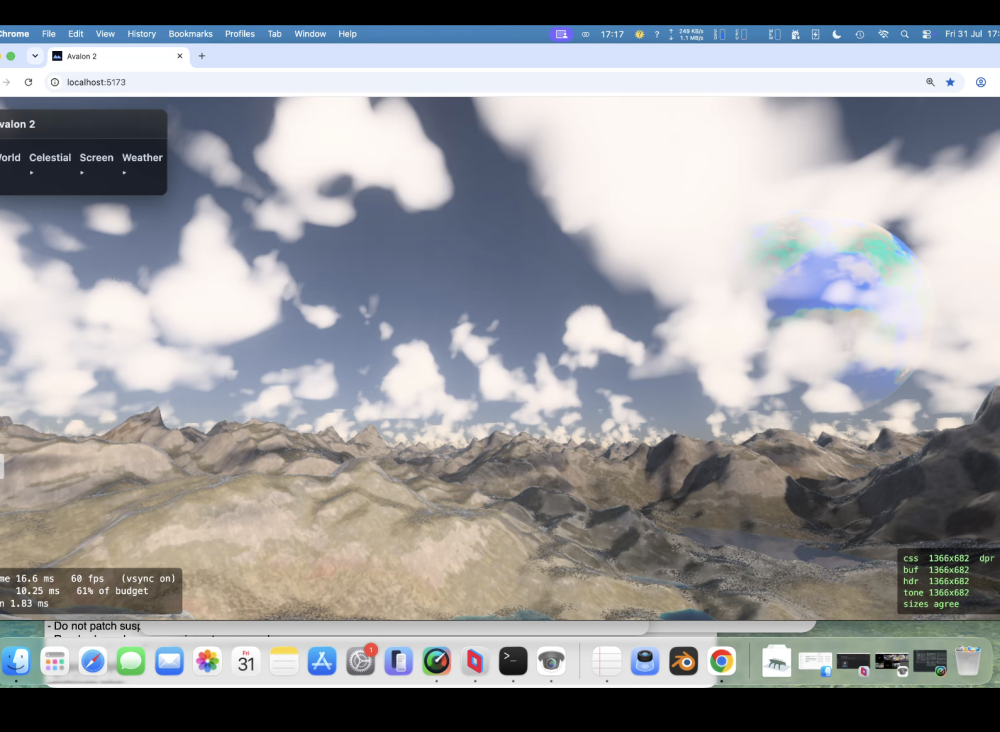
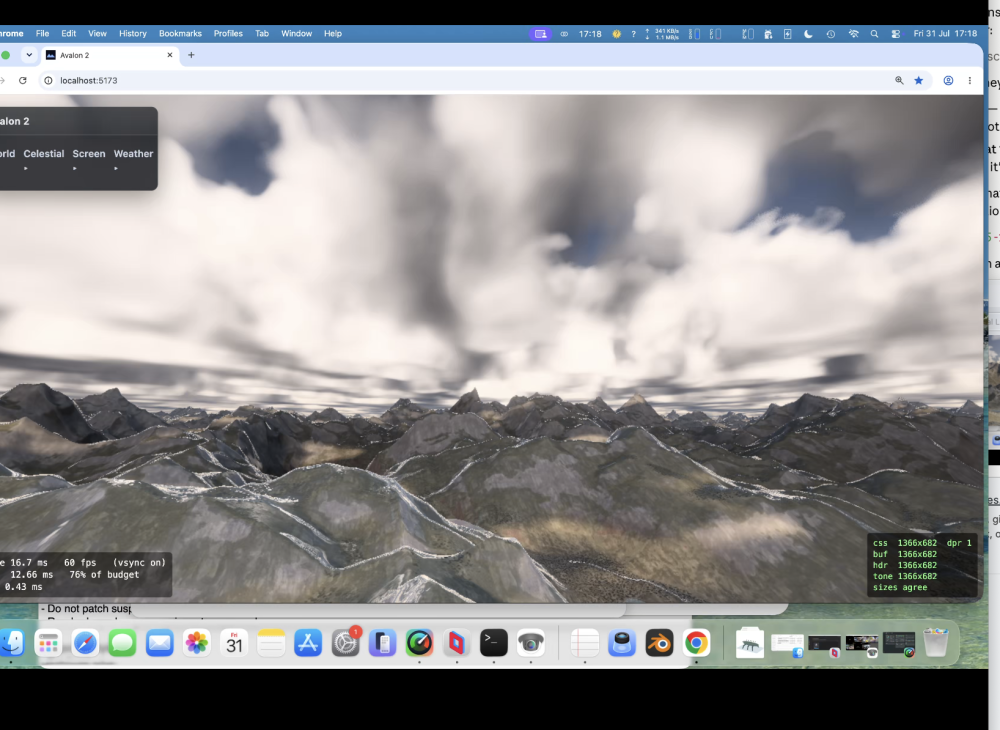
PUKE now does God rays, lightening storms, ambient occlusion , terrain can influence cloud colours and likewise; same for water etc. So all in the same render pipeline. Limits in webgpu are no more than 16 sampler passes for the march. This limit has been a constant problem. Also back at a crippling frame rate if you have max clouds/max rain and a lightening storm and decide to look at a grazing angle over water!.
-
Pocster's Unreal Kafkaesque Engine P.U.K.E (tm)
-
Oh yes and the amazing cube marched clouds. VERY expensive! need to optimise again soon !. Lit!, can have a nice storm with them! Which means a detour (as usual) to .... lightening!!!
-
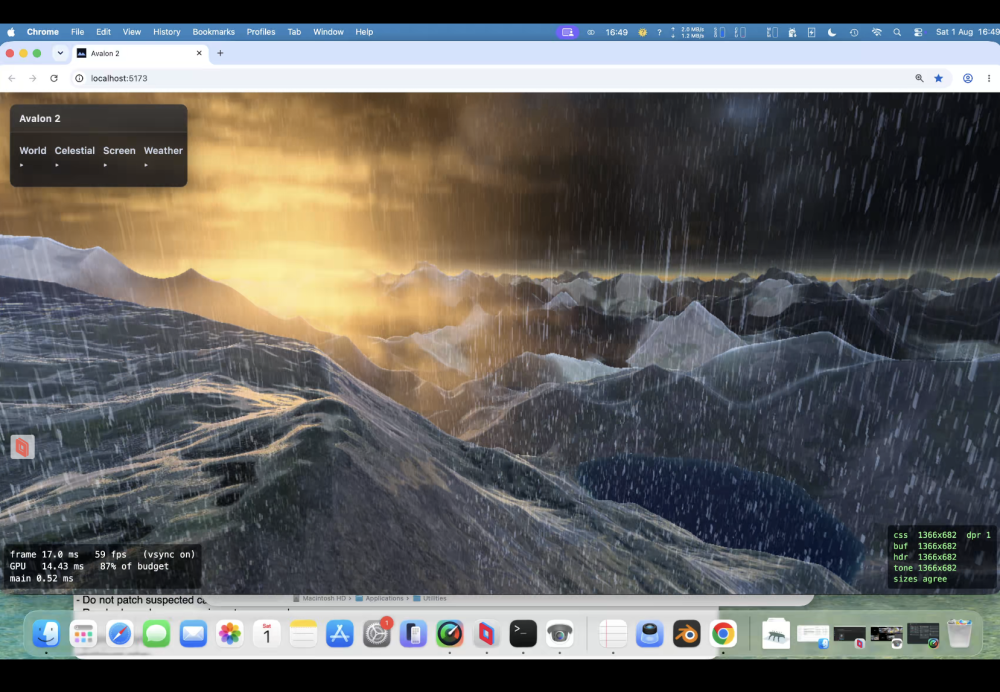
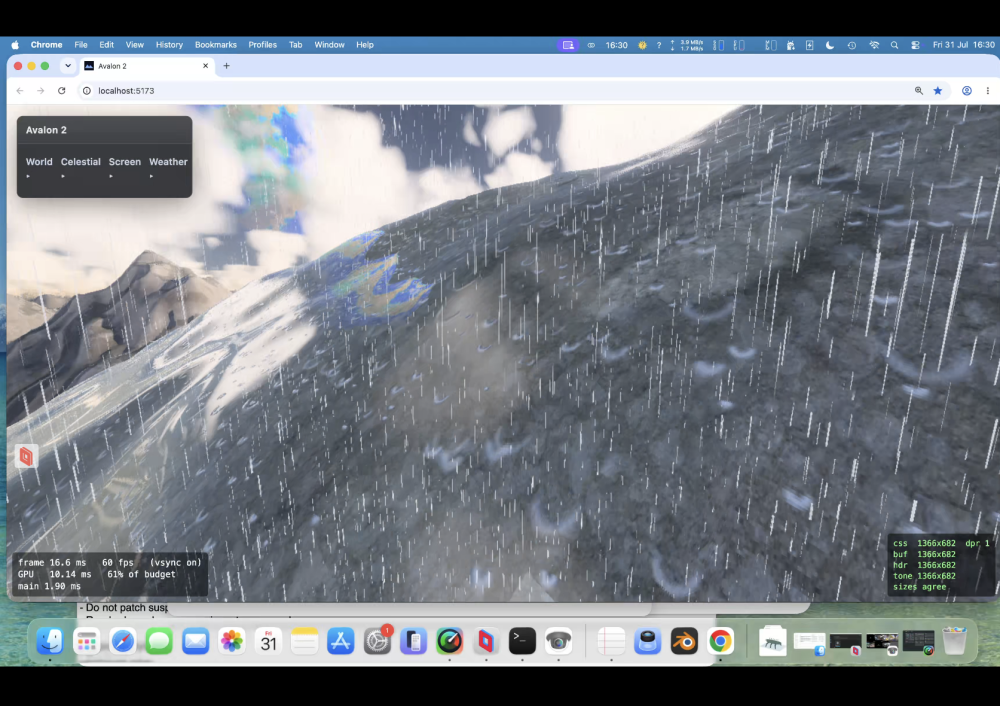
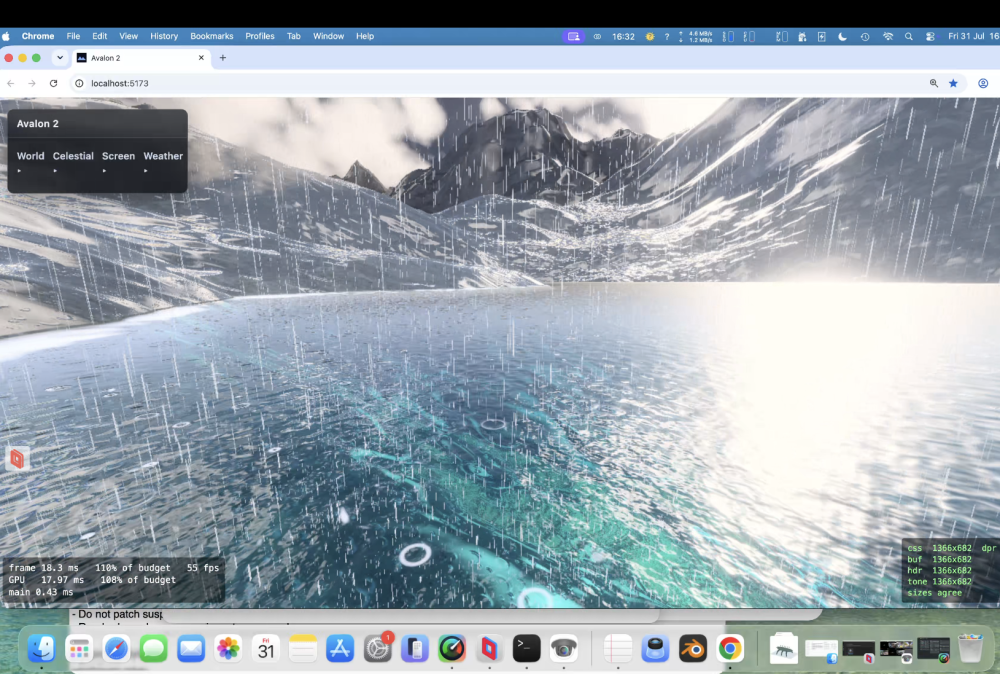
Taken all day to get right ; Claude wants to quit many times! Heavy rain actually runs down slopes! Looks fantastic. I dont think even the might Unreal Engine does this.
-
10% gpu; yep!. 25% if you get the worst possible grazing angle over water. Added upscale (for some minor quality loss) even on the water grazing angle if I drop to 70% gpu at 13%, drop to 50%, gpu 10% Plenty of engine for more fun!
-
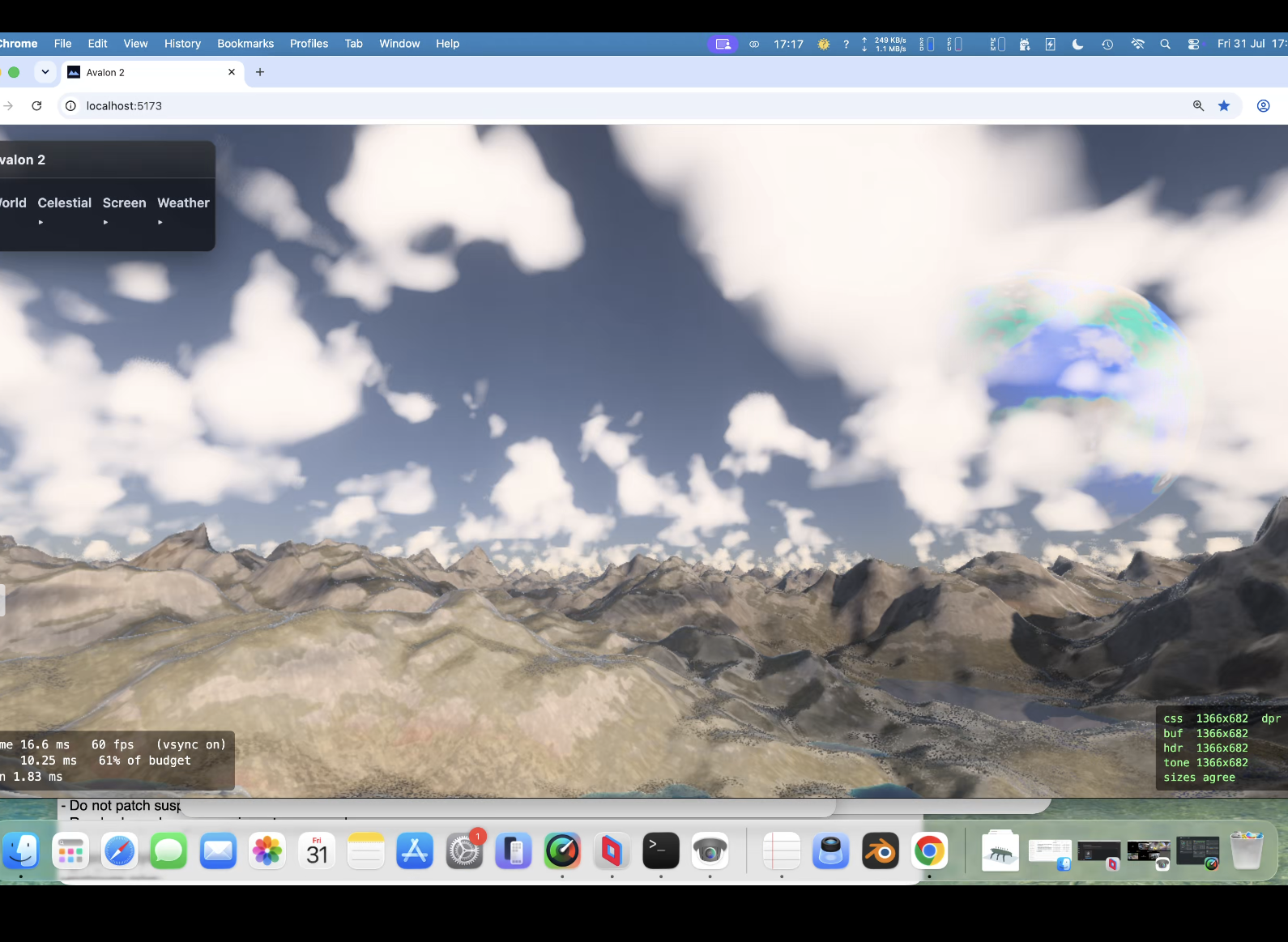
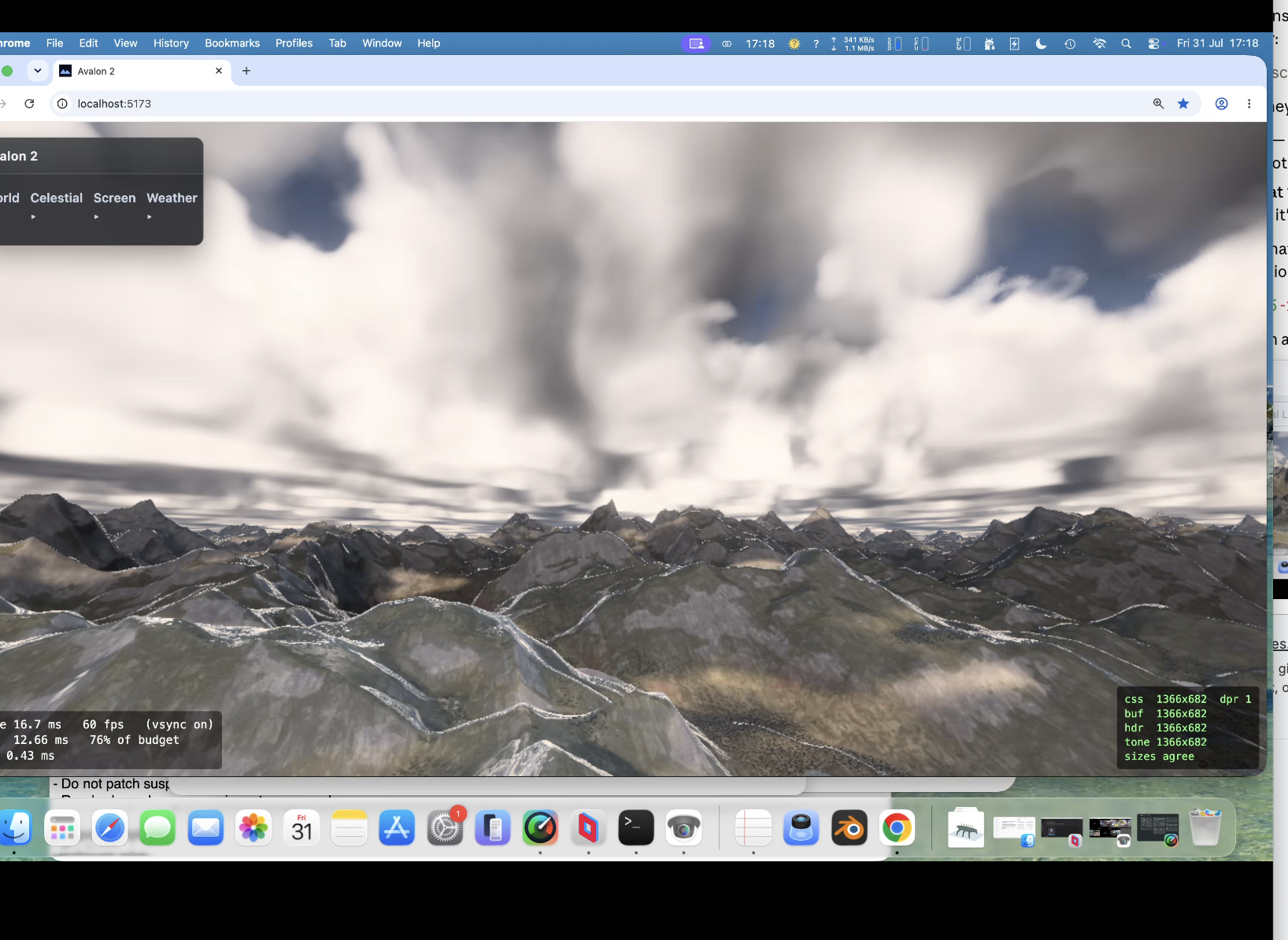
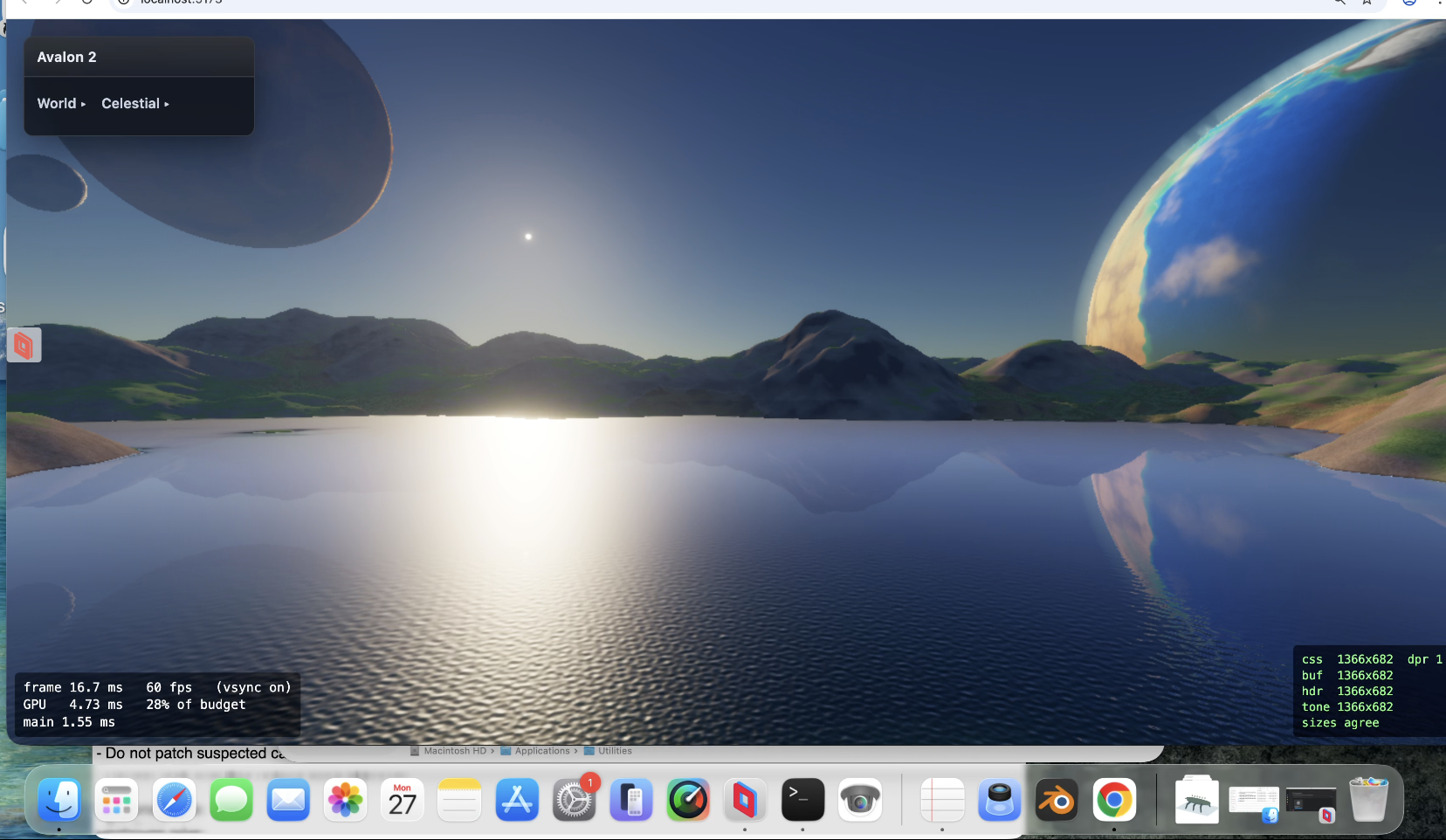
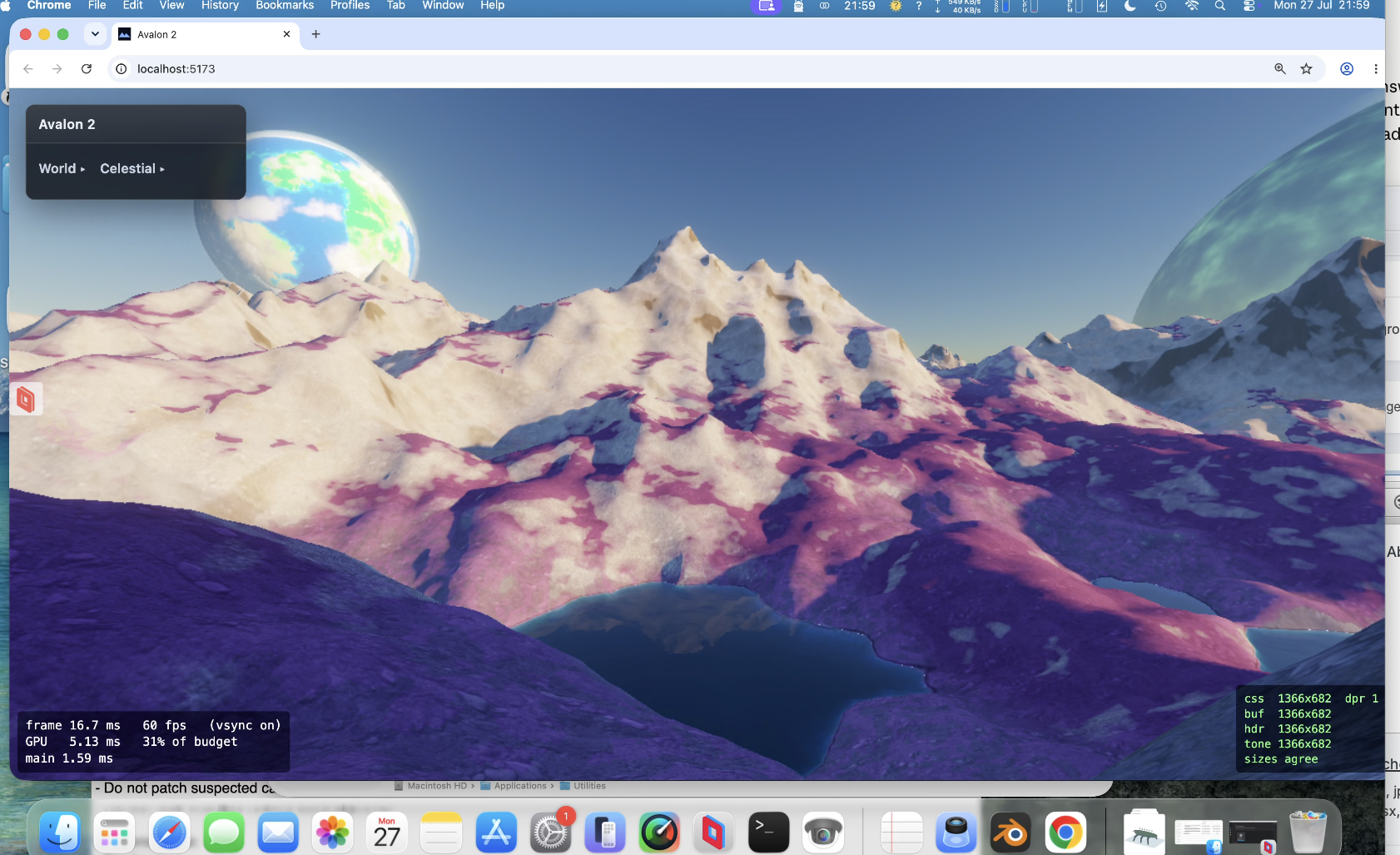
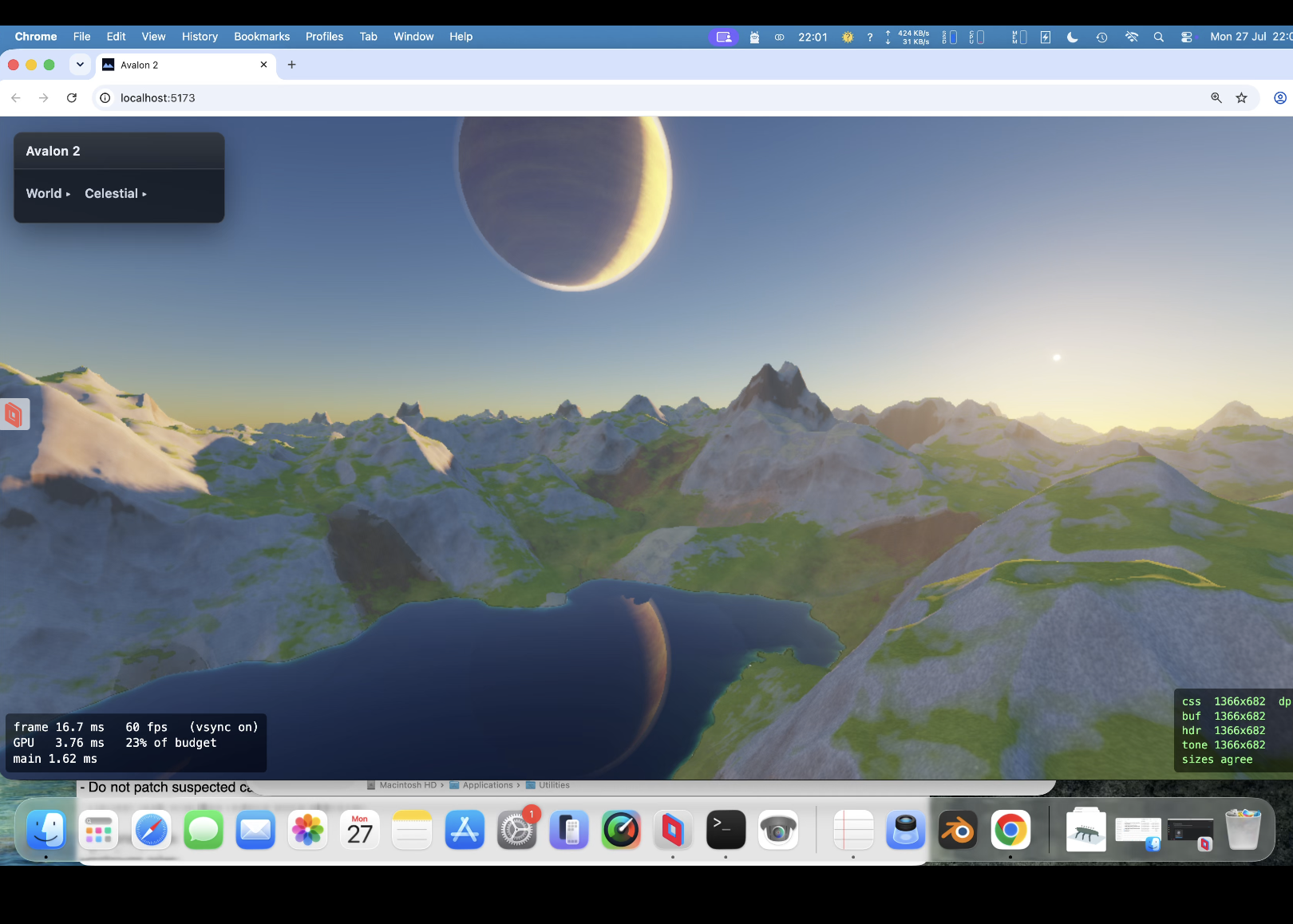
Hit 50% gpu with procedural background planets/nebula/stars. So optimise , optimise, optimise. Took a while now back at around 30% gpu. Proper (frustrating) exposure aswell. So when you look at something really bright you are blinded for a bit and colour 'seaps' back in. Trying to function like an eye rather than a camera (so binned lens flare). Going for clouds again (3rd attempt) - tricky one but got a 25 page spec for it. Then more fun... always bugged me with a height map that of course you cant have arches/overhangs/caves but have another spec for a hybrid system that allows such things. Another sped up thing was that the baking was taking upto 4 seconds (which bugs me) ; down to 1 second now. So startup is far quicker.
-
I'm not building houses any more Uncle Nick - I'm building worlds!
-
Horrific bugs I'd never had found. Absolute bitches - well above my pay grade. But.....better than my holiday snaps!
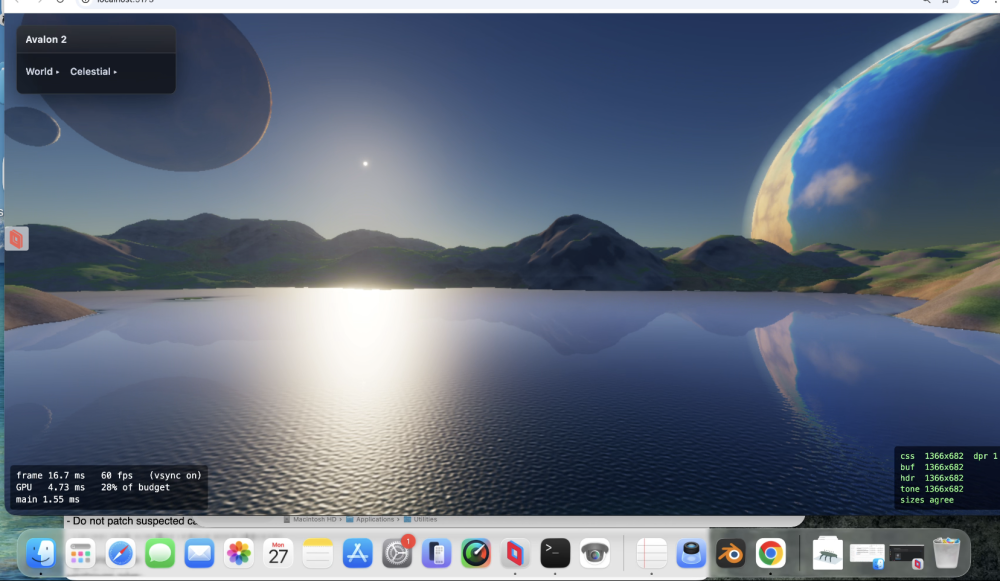
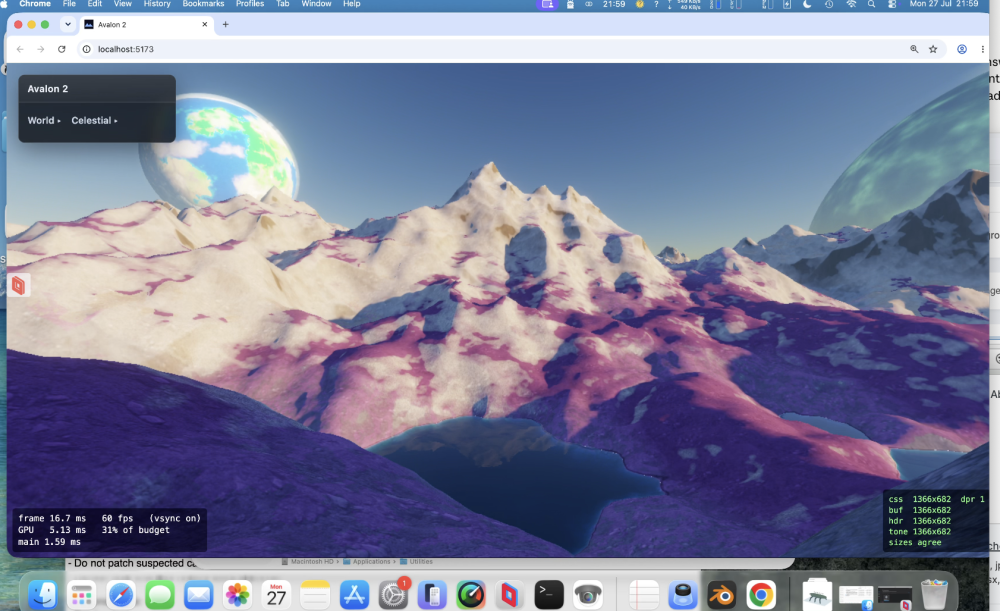
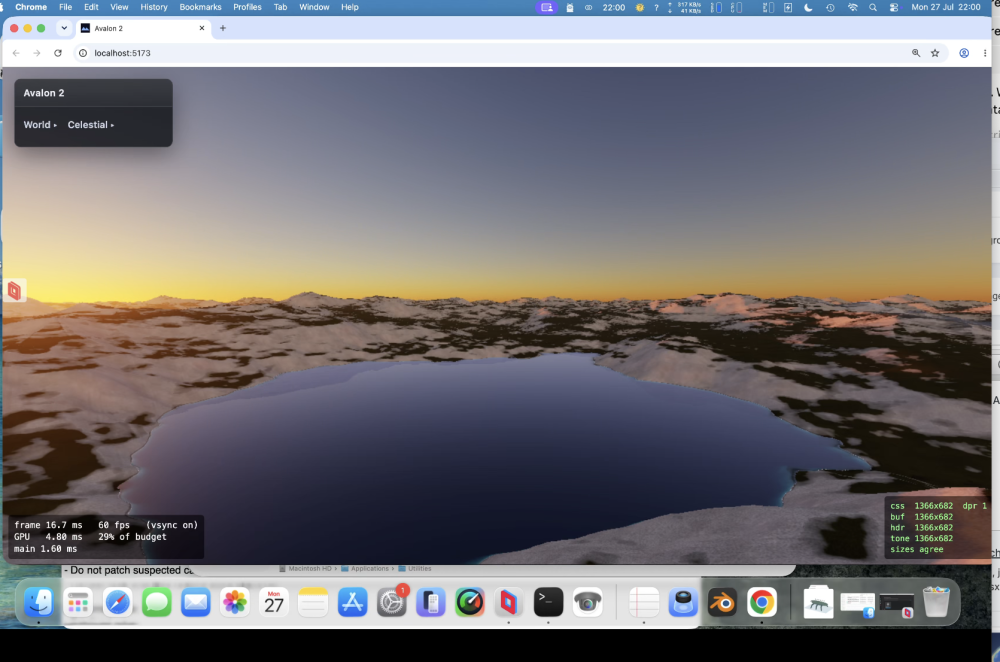
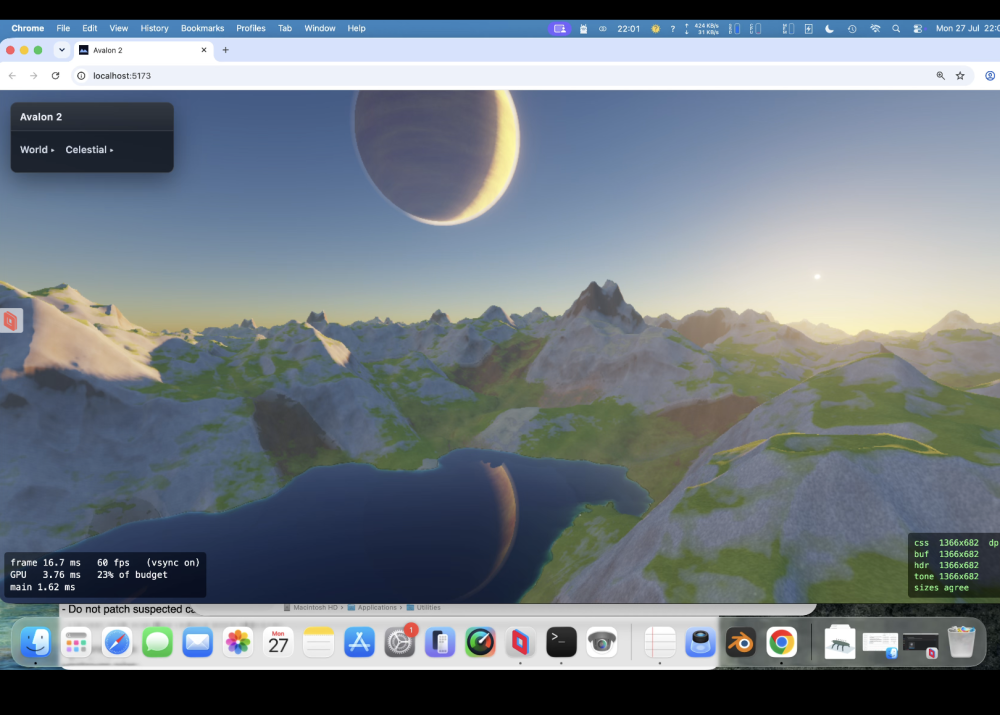
-
Claude not being so good today. Causing more problems than it fixes. Adding and removing without my knowledge...
-
gpu at 50% thats with a grazing angle view (worse case for ray march) , water on screen, bloom. So a best case of a worst case. So optimise time. I reckon I can get that 50% down to 25% by pre-baking as much as possible in the terrain that gives a noticeable gain. 320Mb about to be burnt (insane when you think about it just how much 320Mb is , nowadays viewed as nothing)
-
No one and I mean no one fully understands quaternion maths … it’s magic maths !